在开发机器学习项目时,首先我们需要选择合适的模型架构,然后训练。通常情况下我们第一次选择的模型并不会满足我们的期望,所以训练完后我们会对模型进行评估分析,在下一轮训练中使用更好的参数或方法,如此循环。
错误分析与添加数据
错误分析是在评估模型时常用的手段,我们可以通过分析模型在交叉验证集中的错误来找到模型的弱项,可以通过添加那个类别的数据集来增强模型。除此之外,还可以使用数据增强来增强模型的准确率。数据增强经常被使用在图像识别模型的训练中,例如旋转图像、放大缩小图像等等手段。需要注意的是,对训练集的数据增强应该对应验证集中可能出现的干扰类型。
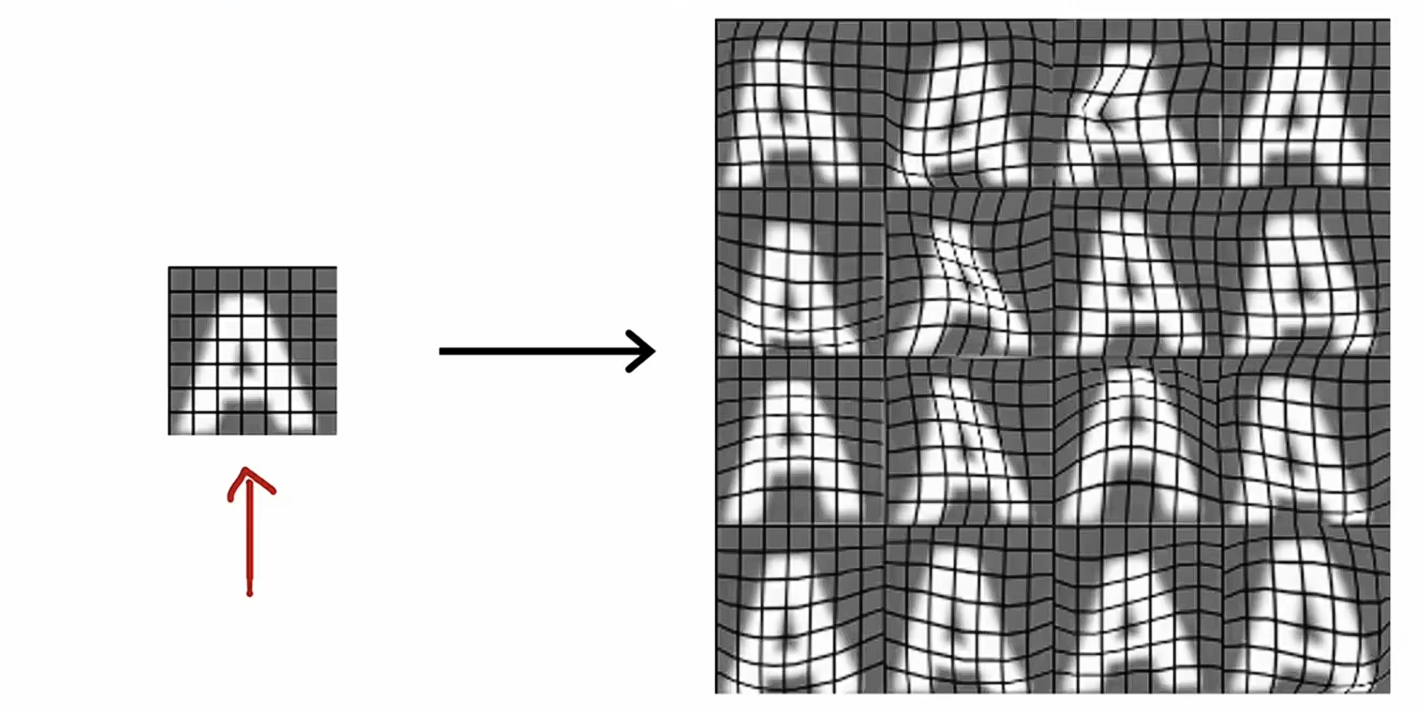
还有一种技术叫做数据合成,通过生成全新的数据补充数据集。以 OCR 为例,我们需要模型在图片中读到文本,当图片数据不够的时候,我们可以使用电脑文本编辑器的不同字体,并使用不同颜色、大小、对比度的图片作为基础训练集。
迁移学习
对于数据量小的训练任务,迁移学习是一种很有效的训练方法。假设我们现在要训练手写数字识别,但是我们能找到的数据量很小,不过我们有一个数据量很大的分类数据集。我们可以先将模型在这个很大的数据集上训练,然后将训练好的神经网络的输出层用手写数字样本重新训练,这样就可以使用少的训练样本获得更好的模型。值得注意的是,源任务和目标任务越接近,迁移学习通常越有效。
有两种重新训练的方法:一是只训练最后几层,把输出层换掉,只训练新层。这种方式计算量小,适用于小数据集。二是先用预训练权重初始化模型,再用自己的数据对全部参数或者部分参数继续训练。这种方式通常效果更好,但也更容易过拟合,对学习率设置要求更高。
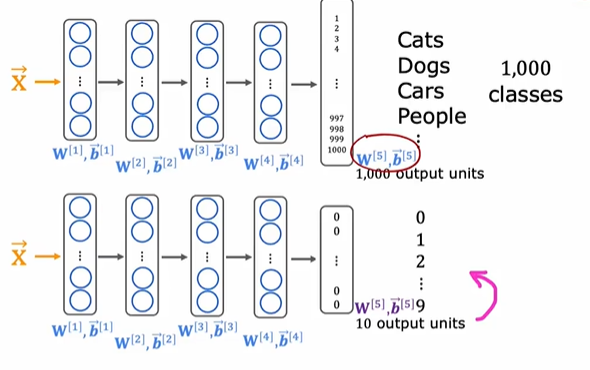
迁移学习的好处是我们可以不用从头训练一个新模型。一些开发人员使用海量数据训练了一个神经网络并将其发布在网上,这样我们只需要替换输出层并重新训练就可以得到类似的效果。
机器学习项目的完整周期
让我们以语音识别项目为例,来认识一个机器学习项目的完整周期。
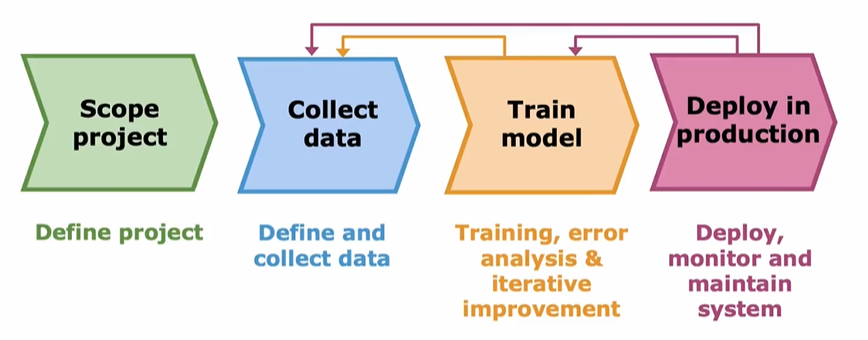
机器学习项目的第一步是确定项目范围,决定项目的具体内容和要解决的问题。接下来需要收集用于训练模型的数据。然后就要训练模型了,按照文章一开始说的步骤循环迭代,直到模型效果接近优秀标准线。最终部署到生产环境中供用户使用。
倾斜数据集
倾斜数据集指的是很不平衡的样本,也就是一类样本特别多,另一类样本特别少,只看 准确率(accuracy) 往往会得出错误结论。比如正样本只占很小一部分,模型就算把所有样本都预测成负类,准确率也可能看起来很高。
因此我们引入精确度和召回率。我们接下来就以二分问题为例解析一下这两个指标。
精确度指的是模型判成正类的这些样本里,真正是正类的有多少。其计算公式如下:
$$
\mathrm{Precision} = \frac{TP}{TP + FP}
$$
其中:
- TP:真正例,本来是正类,也被预测成正类
- FP:假正例,本来是负类,却被预测成正类
召回率指的是所有真正的正类样本里,模型成功找出来了多少,其计算公式如下
$$
\mathrm{Recall} = \frac{TP}{TP + FN}
$$
其中:
- FN:假负例,本来是正类,却被预测成负类
当我们怕模型误报时(如垃圾邮件检测),应该看重精确率;当怕模型漏报时(如癌症筛查),应该更看重召回率。
F1-score
F1-score 可以将精确度和召回率结合起来计算出一个新的评价指标
$$
F_1 = \frac{2 \times \mathrm{Precision} \times \mathrm{Recall}}{\mathrm{Precision} + \mathrm{Recall}}
$$
F1-score 的核心特点是:只有当 Precision 和 Recall 都比较好时,F1 才会高。
F1-score 用的是调和平均数,不是普通平均数,因此他会受更小的那个值影响。F1-score常常用于倾斜数据集训练时的模型的评估。