在我们训练了一个模型之后,如何去评估这个模型是否符合我们的标准呢?接下来让我们来看一下常用的一些方法。
训练集与测试集
在所有的数据集中,我们将其分为 训练集 和 测试集。顾名思义,训练集就是模型在训练时所使用的数据,测试集就是训练完成的模型再使用的数据。一般来说训练集占原数据集的 70% - 80%。
为了量化一个模型在测试集上的表现,使用的代价函数如下所示:
$$
J(\vec{w}, b) = \left[ \frac{1}{2m_{\text{test}}} \sum_{i=1}^{m_{\text{test}}} \left( f_{\vec{w},b}\left(\vec{x}^{(i)}\right) - y^{(i)} \right)^2\right]
$$
另外一个常用的数据是训练误差,可以表示模型在训练集上表现如何,其计算公式如下所示
$$ J_{train}(\vec{w}, b) = \frac{1}{2m_{train}} \sum_{i=1}^{m_{train}} \left( f_{\vec{w},b}\left(\vec{x}_{train}^{(i)}\right) - y_{train}^{(i)} \right)^2 $$交叉验证集
交叉验证机是一种介于训练集和测试集之间的一份数据,起主要作用不是训练模型,也不是评估模型,而是帮助我们在训练过程中选择更合适的模型和参数。
当我们在不断地调整模型时,如果每次都用测试集来查看效果,那么最后其估计效果会高于实际的泛化效果,所以就要单独再分出一部分数据,作为交叉验证集。
比如我们正在做多项式回归模型,我们可以用训练集分别训练 n 次多项式,用交叉验证集计算误差,选误差最小的模型,最后再用测试集做评估。
其使用的代价函数如下,称为验证误差:
$$ J_{cv}(\vec{w}, b) = \left[ \frac{1}{2m_{cv}} \sum_{i=1}^{m_{cv}} \left( f_{\vec{w},b}\left(\vec{x}_{cv}^{(i)}\right) - y_{cv}^{(i)} \right)^2 \right] $$训练集选择参数,交叉集选择模型,测试机不参与模型决策所以可以给出客观模型评估。
偏差与方差
构建机器学习系统的关键是决定做什么来提高整个系统的性能。查看学习算法的偏差和方差可以很好的指导我们下一步该做什么。
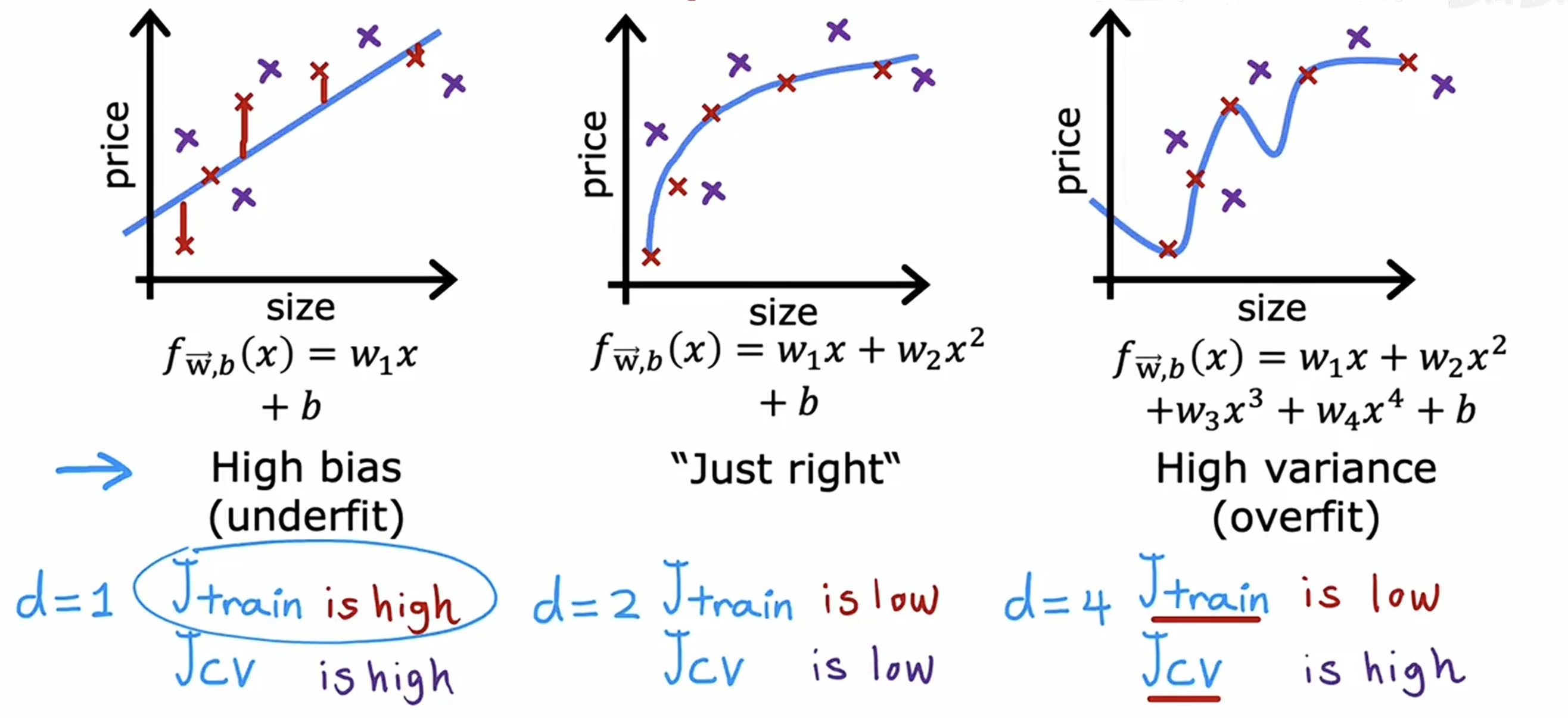
当一个模型欠拟合时,训练集和验证集的代价函数都很高;过拟合时,训练集的代价函数值会比较低,验证集的代价函数值会比较高,具体如下图所示
随着模型的多项式次数增加,验证集和训练集呈现出如下的趋势:
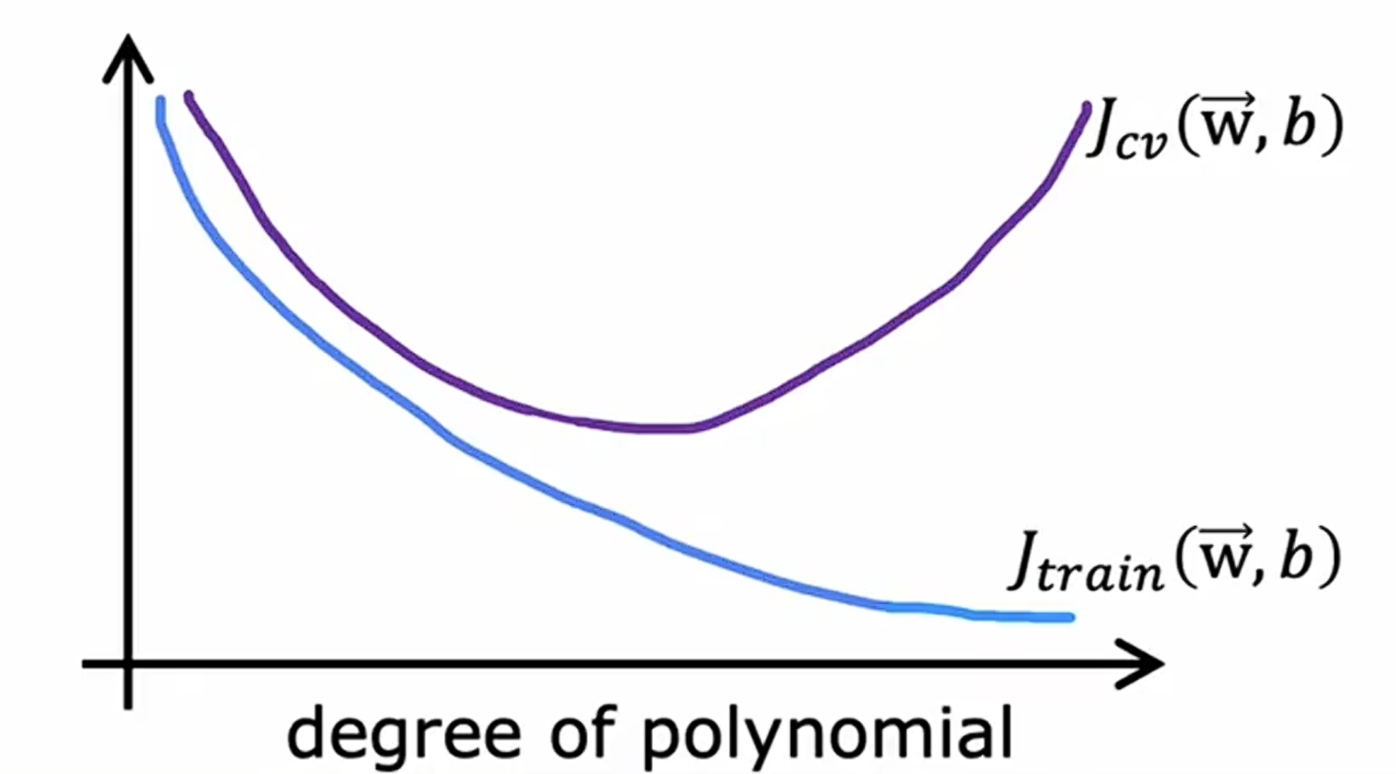
在上图中可以认为,如果训练集代价函数值高并且约等于验证集代价函数值,可以认为这个模型具有高偏差,欠拟合。如果训练集代价函数值远大于验证集代价函数值,可以认为这个模型具有高方差,过拟合。
通常情况下,加入正则化后会使得模型的偏差增大,方差减小。在线性回归中加入 L2 正则化后,会惩罚过大的参数,让模型更平滑,更简单。当模型变得简单时,就难以学习真实规律,会导致欠拟合风险增大。同时,正则化会让模型对数据不那么敏感,这样子模型的过拟合风险减小,泛化能力更强,方差减小。
建立基准性能水平
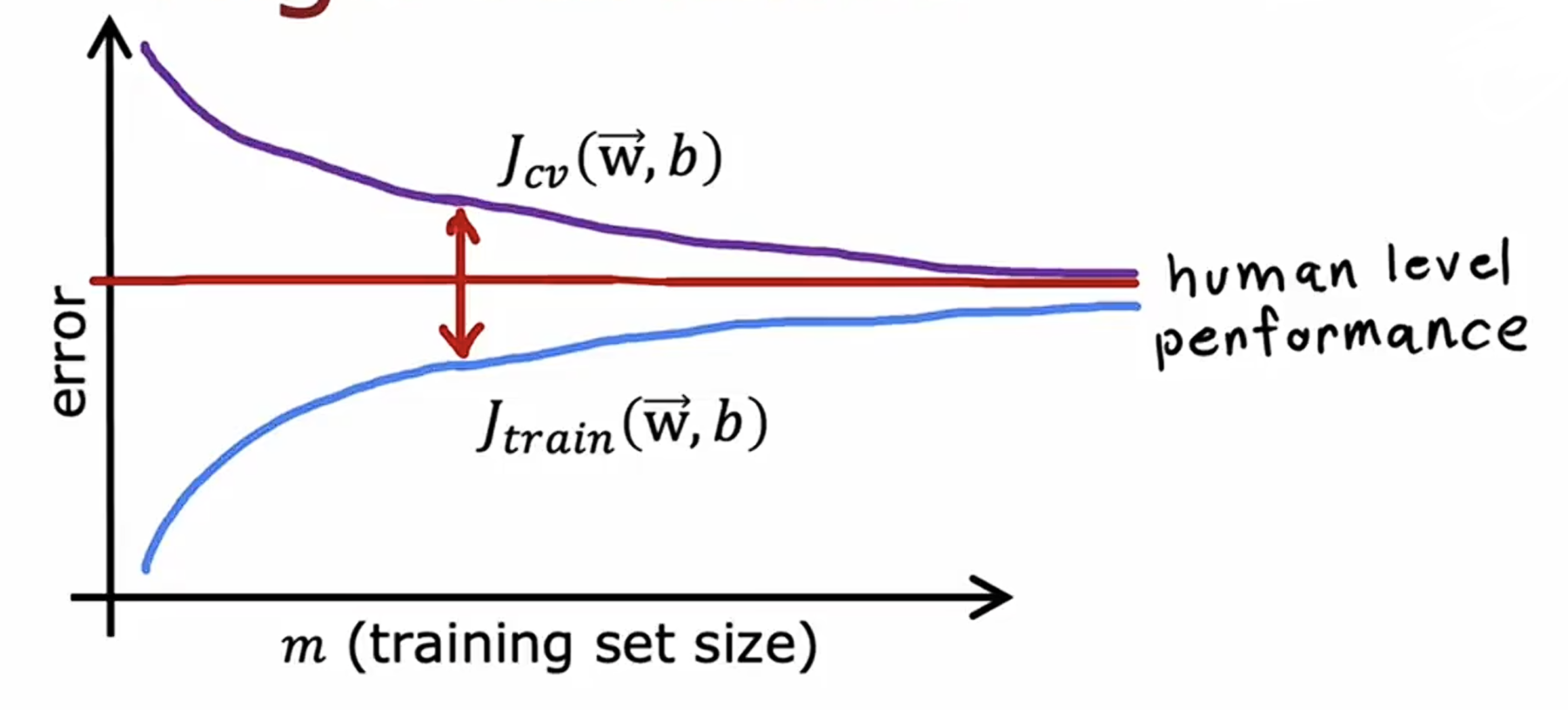
当判断训练误差高低时,应该建立一个基准性能水平。例如语音识别的时候,可以将人累转录错误率作为基准水平来判断一个模型的好坏。
正如刚刚所说,简历基准性能水平的一个常见方法就是测量人类在某个任务上的表现,也可以将竞争模型的水平作为基准,也可以根据经验猜测基准水平。
学习曲线
以训练集大小作为横轴,训练集代价函数值和验证集代价函数值作为纵轴,可以得到如下图像
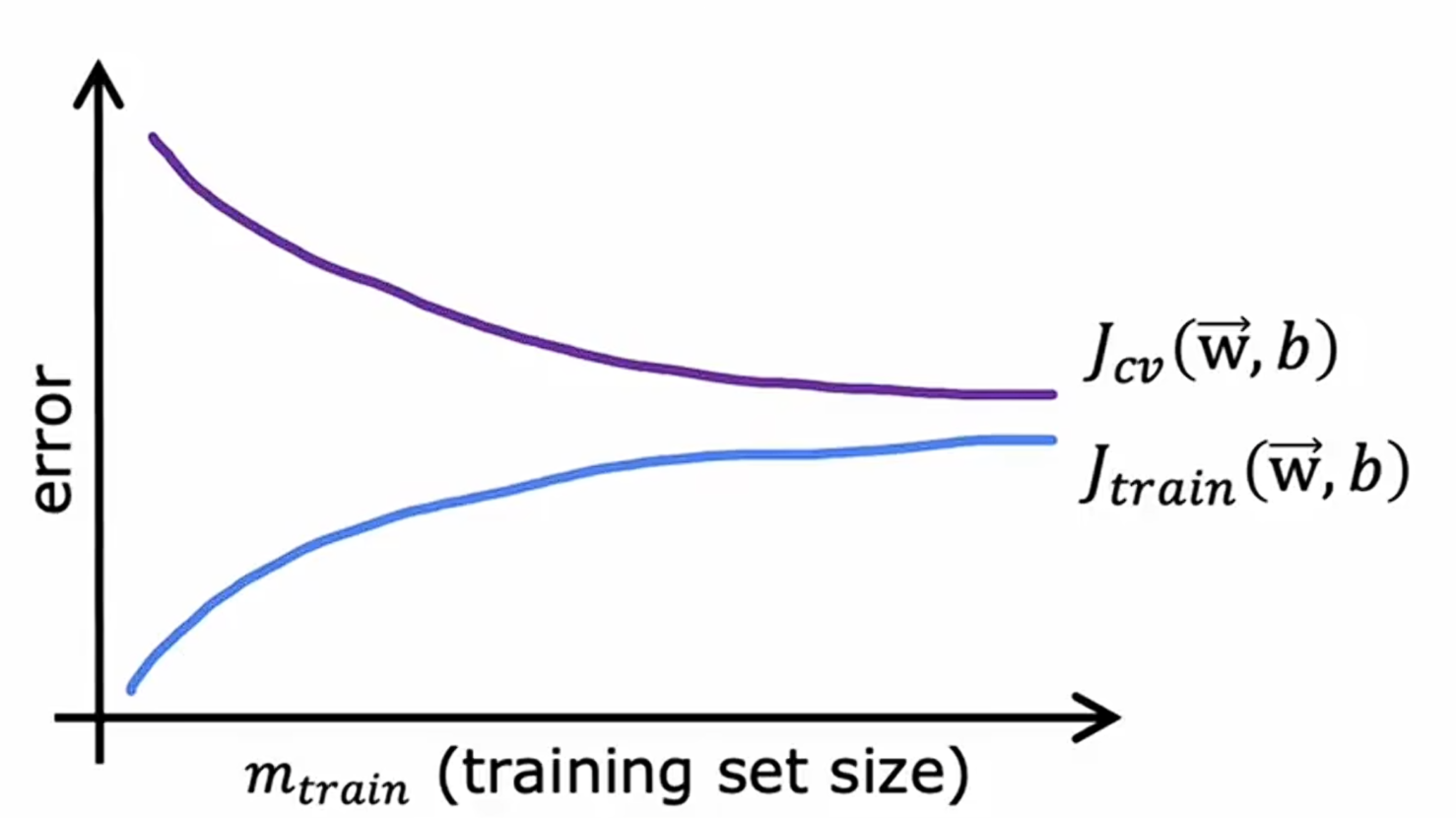
在一定情况下,样本数越多,对训练集的完美拟合就越来越难,而模型的泛化能力也就会越来越强。
但是当一个简单时(即具有高偏差),验证集的代价函数值可能会一直持续远高于基准值,并且随着训练集数量的增加而趋于平缓,降不下来,这时候就需要一个更复杂的模型。
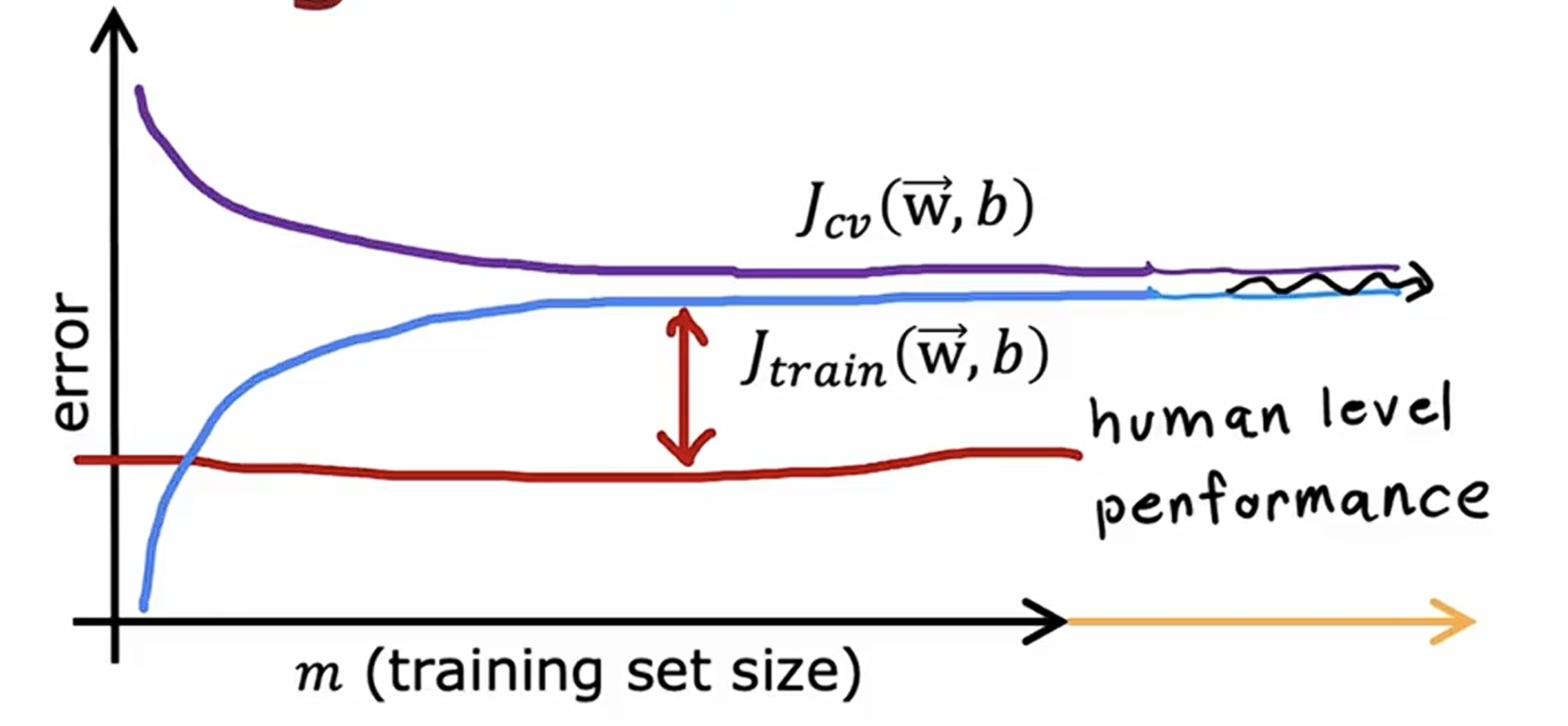
当一个模型过于复杂时(即具有高方差),尽管他很好的拟合了训练集的数据,但是当训练集过少时会导致你的验证集代价函数值过大。增大训练集数量就可以降低验证集代价函数值,最后可能会趋近于基准水平。