决策树
下图是一个简易的决策树模型,用来检测一张图片的内容是否为一只猫。在这个决策树中,Ear shape 被称为根节点,所有的椭圆形被称为决策节点,最终的方框型节点被称为叶节点。
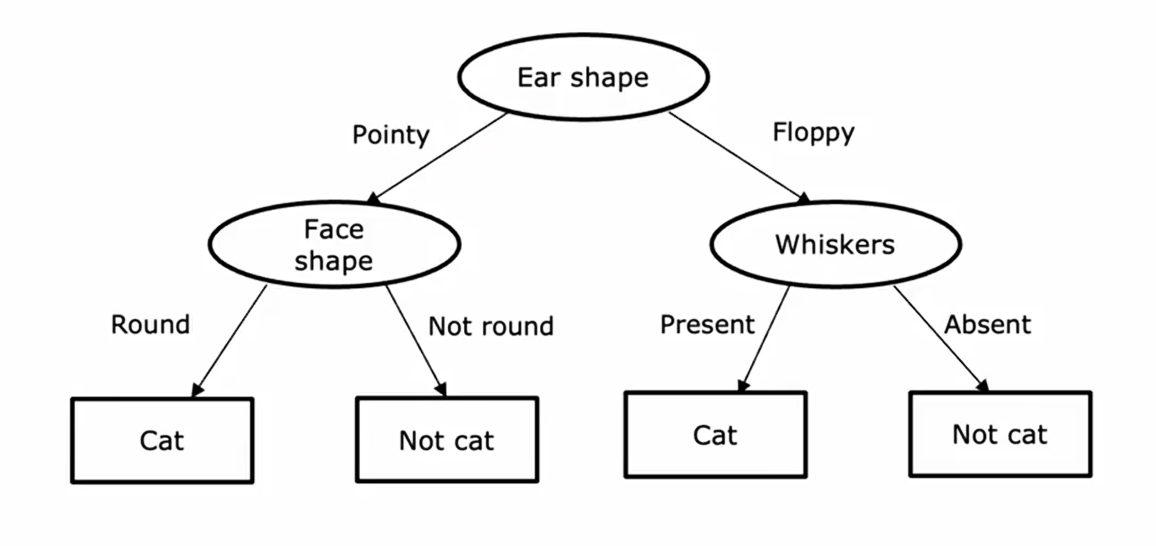
构建决策树时最关键的问题是每一步应该选择哪个特征来划分数据。当有多个特征时,我们需要一个标准来判断依照哪个特征划分后效果最好。
假设我们要判断是否适合打球,原始数据中打球和不打球各五个。如果按照 “天气” 划分后,晴天大多数不打球,阴天全部打球,雨天大多数不打球,那么每组内部的结果就更统一了,说明这个特征更有用。所以选择决策特征的关键因素是,决策后,子节点尽量单一。
为了衡量一个样本集的纯度,我们引入熵的概念,其计算公式如下:
$$
H(D) = - \sum_{k=1}^{K} p_k \log_2 p_k
$$
其中,D 表示当前数据集,p_k 表示第 k 类样本所占的比例。熵越大,数据越混乱,熵越小,数据越纯净。

我们常常使用 ID3 算法来选择决策特征。信息增益则表示了划分前后混乱程度减少了多少
$$
Gain(D, A) = H(D) - H(D|A)
$$
$$
\text{信息增益} = \text{划分前的混乱程度} - \text{划分后的混乱程度}
$$
信息增益越大,说明这个特征划分效果越好。ID3 算法就是每次选择信息增益最大的特征。
但是 ID3 也有一个问题,它容易偏向取值很多的特征。比如“学号”这个特征,每个人都不一样,用它划分后,每个节点可能只有一个样本,看起来非常纯,但实际上没有泛化能力。因此我们引入 C4.5 信息增益率,公式如下
$$
GainRatio(D, A) = \frac{Gain(D, A)}{IV(A)}
$$
其中,IV(A) 表示特征 A 的固有值,也可以理解为特征 A 本身取值的复杂程度。特征取值越多,IV(A) 通常越大,因此信息增益率可以在一定程度上抑制 ID3 偏向多取值特征的问题。
构建决策树一般按照下面的步骤:
1. 从根节点开始,把所有训练数据放进去
2. 计算每个特征的划分效果
3. 选择最优特征进行划分
4. 对每个子节点重复上述过程
5. 直到满足停止条件
6. 得到最终的决策树
可以理解成递归过程:
构建决策树(当前数据集):
如果当前数据已经足够纯:
返回一个叶子节点
如果没有特征可用:
返回多数类作为叶子节点
找到最优划分特征
根据该特征把数据分成多个子集
对每个子集继续构建决策树
我们还需要设置决策树的停止条件,例如当前节点中的样本已经属于同一类、没有更多特征可以划分、树的深度达到上限、当前节点样本数量太少、划分带来的提升很小等等。
如果一个分类特征可以取 K 个可能值,那么我们可以用 K 个二元特征值替换他。例如原问题是判断水果类别,输入为苹果、香蕉、橘子,那么就可以将其拆分为三个问题
- 是不是苹果?
- 是不是香蕉?
- 是不是橘子?
分类回归树(CART)
CART 同时支持分类任务和回归任务。
CART 的一个重要特点是:每个节点只分成两个分支,也就是每次只做一次“是 / 否”判断。对于连续特征,CART 通常使用类似“特征值是否小于等于某个阈值”的方式划分;对于离散特征,CART 可以使用类似“是否属于某个取值集合”的方式划分。
CART 做分类任务时,常用基尼指数 Gini 来选择划分特征,其公式如下
$$
Gini(D) = 1 - \sum_{k=1}^{K} p_k^2
$$
其中,D 表示当前数据集,p_k 表示第 k 类样本所占的比例,K 表示类别数量。Gini 越小,说明数据越纯。
当 CART 尝试某个划分条件时,会把数据分成左右两个子节点,并计算划分后的加权 Gini:
$$
Gini_{split} =
\frac{|D_{left}|}{|D|}Gini(D_{left})
+
\frac{|D_{right}|}{|D|}Gini(D_{right})
$$
CART 会尝试不同的特征和划分点,最终选择让加权 Gini 最小的划分方式。
CART 做回归任务时,使用平方误差,让每个子节点中的 y 值尽量接近。
和上文中的 ID3 / C4.5 相比,CART 用二叉树结构,既能分类也能回归。
回归树
回归树就是用决策树来解决回归问题,分类树预测的是类别,而回归树预测的是连续数值。回归树不能用类别纯度,因为其预测的是连续值,所以常用 均方误差 MSE:
$$
MSE = \frac{1}{m}\sum_{i=1}^{m}(y_i - \bar{y})^2
$$
其中:
- $y_i$:第 $i$ 个样本的真实值
- $\bar{y}$:当前节点中所有 $y$ 的平均值
- $m$:当前节点中的样本数量
MSE 越小,说明这个节点里的数值越接近。
回归树的构建过程是
1. 从根节点开始
2. 尝试不同特征和划分点
3. 选择让误差最小的划分
4. 继续递归划分
5. 到叶子节点后,用该节点样本 y 的平均值作为预测值
随机森林算法
随机森林算法是在决策树基础上发展出来的一种集成学习算法。单棵决策树容易受训练数据影响,可能出现过拟合;随机森林通过训练很多棵不同的决策树,再把它们的结果综合起来,从而让模型更稳定。
例如我们需要判断一张图片是不是猫,单棵决策树可能会这样判断:耳朵形状 → 脸型 → 胡须 → 是否是猫。但是一棵树可能会判断错,所以我们训练多种类的树,让这些树都做出判断,最后如果认为是猫的树更多,就判断为猫。
随机森林里面的“随机”主要体现在两个地方。
**1、随机抽取训练样本。**每棵树训练时不使用完整训练集,而是从训练集中有放回的随机抽样。
**2、随机选择特征。**每棵树在选择划分特征时,不是从所有特征中选最优特征,而是先随机选出一部分特征,再从这部分特征中选择最优划分。
随机森林的优点有
准确率通常比较高
不容易过拟合
可以处理分类和回归问题
对特征缩放不敏感
可以评估特征重要性