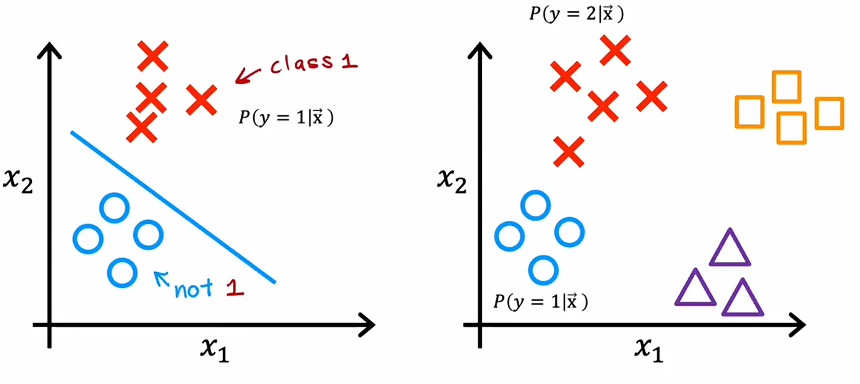
多类别
在实际情况中,模型输出的类别往往是多种多样的。
softmax 回归算法
softmax 是逻辑回归的推广,用于解决多分类问题。让我们来看看 softmax 回归是如何实现的。
假设有 n 个输出类别,那么通过以下式子先做 n 次线性变换:
$$
z_i = \vec{w}_i \cdot \vec{x} + b_i
$$
接下来通过下面这个式子计算分别是每一类的概率:
$$
a_i = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}} = P(y=i \mid \vec{x})
$$
softmax 的损失函数和逻辑回归很接近,被称为稀疏分类交叉熵损失函数。其形式如下:
$$
\mathrm{loss}(a_1,\ldots,a_N,y)=
\begin{cases}
-\log a_1, & \text{if } y=1 \\
-\log a_2, & \text{if } y=2 \\
\vdots & \\
-\log a_N, & \text{if } y=N
\end{cases}
$$
带有 softmax 的神经网络
一般情况下在处理多分类问题时,我们将输出层设置为 softmax 层,并输出多个概率,以便得到最接近正确结果的值。
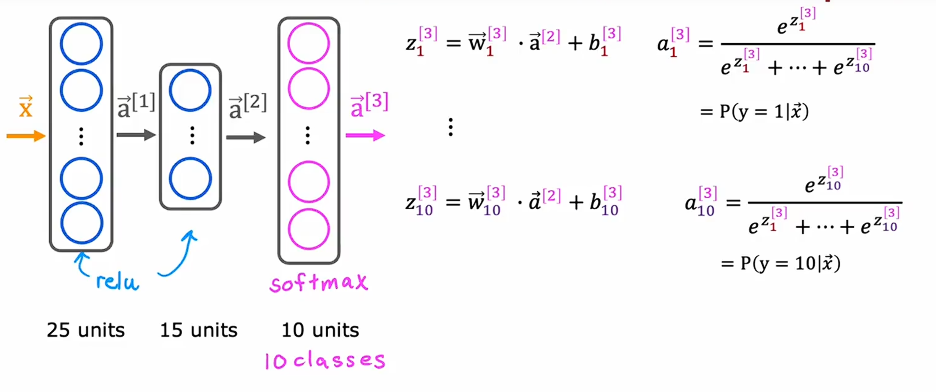
与常见激活函数不同,softmax 中某一类别的输出不仅取决于该类别对应的线性输出,还取决于所有类别的线性输出结果。
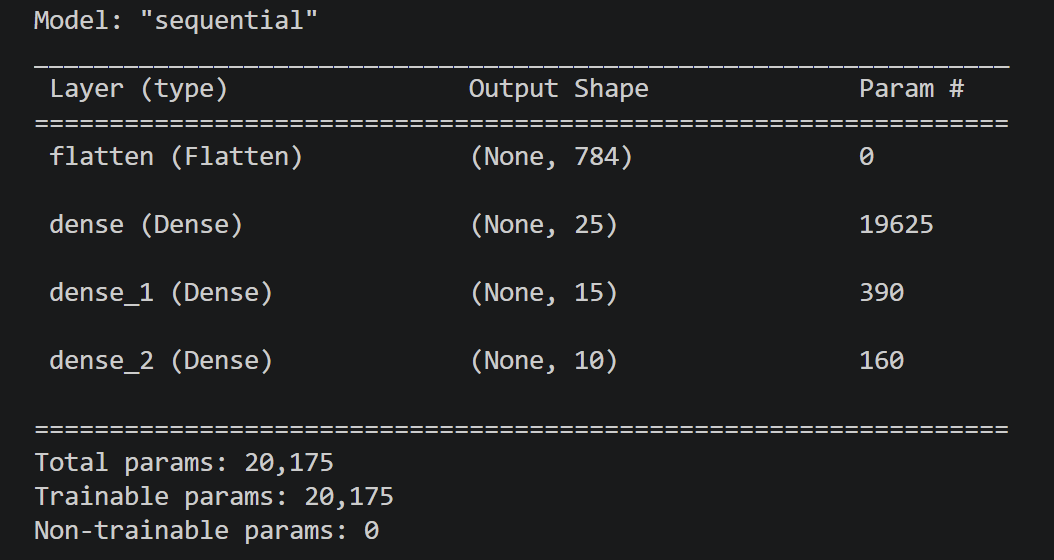
使用 softmax 作为输出层训练手写数字识别模型
完整代码如下,使用 tensorflow 构建神经网络。先将 28*28 的图像归一化处理,然后转换为长度为 784 的连续向量,指明使用稀疏分类交叉熵损失函数,最后训练模型。
1 | import tensorflow as tf |
Adam
在梯度下降的过程中,如果学习率过小,会使模型在同一方向上连续走很多步,花费更长的时间,此时我们可以适当的调大学习率。可是学习率的值是一开始就定好的,我们如何在训练过程中对其进行调整呢?有一种叫 Adam 的算法就可以做到这一点。
Adam算法可以自动调整学习率,其不适用单一的全局学习率,而是为模型中的每一个参数选择合适的学习率。在代码中可以在 compile 中添加 adam 优化器。
卷积层
到目前为止,我们学习的神经网络层都是全连接层,其中每一层每个神经元都从上一层的神经元的激活中获得输入。事实上,仅使用全连接层就可以构建一些非常强大的学习算法。但也有其他的一些类型的层值得我们学习一下。
除了全连接层,另一种常用的层是卷积层。卷积层中的神经单元并不完全依赖上一层的全部输出,通常其中的某个单元只关心上一层输出的局部区域。使用卷积层可以减少算力消耗,使用更少的数据集也可以达到优秀的训练效果。我们会在日后的学习中进一步学习其理论。