回顾
之前我们学习了 RAG 的基本流程,分片、索引、召回、重排、生成。现在我们在 LangChain 环境下尝试一下搭建自己的智能客服。
分片
我们让 chatgpt 生成一份简单的数据集
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| 智能温室系统的核心目标是自动监测环境参数,并根据作物生长需求调节设备状态。常见监测参数包括温度、湿度、光照强度和土壤湿度。
温度传感器用于采集温室内部空气温度。当温度低于 18 摄氏度时,系统可以启动加热设备;当温度高于 30 摄氏度时,系统可以启动风扇进行降温。
湿度传感器用于检测空气湿度。如果空气湿度低于 40%,可以开启加湿器;如果湿度高于 80%,可以适当通风,防止病虫害滋生。
光照传感器用于检测当前光照强度。在阴天或夜间,若光照不足,系统可以自动打开补光灯,以保证植物正常进行光合作用。
土壤湿度传感器用于检测土壤含水量。当土壤湿度低于设定阈值时,控制器会启动水泵进行自动灌溉;当湿度恢复正常后,关闭水泵。
智能温室系统通常由传感器、主控器、执行器和云平台组成。传感器负责采集数据,主控器负责逻辑判断,执行器负责动作控制,云平台负责远程监控与数据存储。
在嵌入式温室项目中,主控器可以使用 STM32、ESP32 或 Linux 开发板。对于需要图形界面、网络通信和多任务处理的场景,Linux 开发板更有优势。
自动灌溉系统的基本流程是:读取土壤湿度数据,判断是否低于阈值,如果低于阈值则启动继电器,继电器再控制水泵工作,从而完成灌溉。
远程监控平台可以显示实时温度、湿度和设备运行状态。用户可以通过网页或手机查看数据,并手动控制风扇、水泵和补光灯。
为了提高系统稳定性,智能温室软件通常采用状态机设计。这样可以将采集、判断、控制、报警等功能划分为不同状态,方便维护和扩展。
|
接下来,我们写下如下代码读取 txt 文件并分片
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| from langchain_text_splitters import RecursiveCharacterTextSplitter
with open("rag_data.txt", "r", encoding="utf-8") as f:
text = f.read()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100,
chunk_overlap=20
)
chunks = text_splitter.split_text(text)
for i, chunk in enumerate(chunks):
print(f"\n--- 分片 {i+1} ---")
print(chunk)
|
写下如上代码,可以从输出看到成功分片了!
索引
现在我们已经有了分片后的 chunks,接下来要做的就是索引,我们先将每个文本块都转变成一串数字向量,然后存入向量库。向量库使用 chromadb 模块。具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import chromadb
from sentence_transformers import SentenceTransformer
model = SentenceTransformer(r"F:\model\paraphrase-multilingual-MiniLM-L12-v2")
print("本地模型加载成功")
client = chromadb.Client()
collection = client.get_or_create_collection(name="rag_collection")
for i, chunk in enumerate(chunks):
embedding = model.encode(chunk).tolist()
collection.add(
ids=[f"chunk_{i}"],
documents=[chunk],
embeddings=[embedding],
metadatas=[{"chunk_id": i}]
)
print("索引建立完成")
|
ChromaDB 是一个向量数据库,主要用来存放文本,存放文本对应的向量,并且可以按相似度检索最相关的内容。一条数据通常有四个部分,唯一标识(id)、原始文本(document)、文本对应的向量(embedding)、额外信息(metadata)。
在这段代码中,client 是和 Chroma 交互的入口,collection 就是 chromadb 中的一个数据集合。
召回
召回阶段,我们将问题也向量化,再使用 ChromaDB 的 query 函数来返回与其相关的 n 个片段。query 函数主要是对 collection 做一次 K 近邻向量检索,使用余弦相似度或欧氏距离来计算两个向量的距离,再返回 K 个有关向量。
1
2
3
4
5
6
7
| query = "温度过高时系统会怎么处理?"
query_embedding = model.encode(query).tolist()
results = collection.query(
query_embeddings=[query_embedding],
n_results=3
)
|
重排
在本次实践中,因为文本量小,所以不进行重排操作。
生成
使用 ollama 在本地部署轻量化的 gamma3 模型,再通过 langchain 调用这个模型。
具体代码如下,至此我们就完成了整个基础 RAG 的流程。
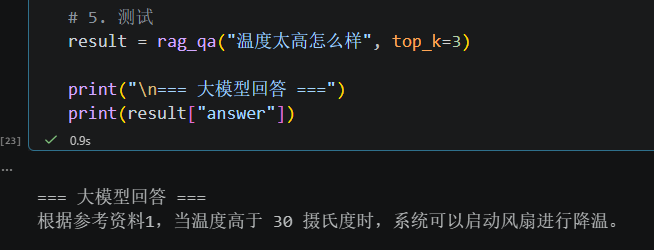
图 1 成功
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
| from langchain_ollama import ChatOllama
llm = ChatOllama(
model="gemma3",
temperature=0
)
def retrieve_docs(query, top_k=3):
query_embedding = model.encode(query).tolist()
results = collection.query(
query_embeddings=[query_embedding],
n_results=top_k
)
docs = results["documents"][0]
metadatas = results["metadatas"][0] if "metadatas" in results else None
return docs, metadatas, results
def build_context(docs):
context_parts = []
for i, doc in enumerate(docs):
context_parts.append(f"参考资料{i+1}:\n{doc}")
return "\n\n".join(context_parts)
def rag_qa(query, top_k=3):
docs, metadatas, results = retrieve_docs(query, top_k=top_k)
context = build_context(docs)
prompt = f"""你是一个问答助手。
请严格根据下面提供的参考资料回答问题。
参考资料:
{context}
用户问题:
{query}
"""
response = llm.invoke(prompt)
return {
"query": query,
"docs": docs,
"metadatas": metadatas,
"context": context,
"answer": response.content
}
result = rag_qa("温度太高怎么样", top_k=3)
print("\n=== 大模型回答 ===")
print(result["answer"])
|