RAG
是什么
RAG 的全称是 Retrieval-Augmented Generation,翻译过来就是 检索 增强 生成。顾名思义,就是先从资料库里检索相关内容,再基于这些内容来生成答案。RAG 是目前最常用的 AI 问答方案之一,很多企业内的知识助手用的都是这项技术。
大致流程
如果你要搭建一个智能客服,必须要有一个大模型。但是当用户提问的时候,大模型并不知道产品的相关信息,因此可以把产品手册和问题一起发送给模型。但是有些产品手册太长了,会导致模型推理时间过长、算力消耗大,因此我们引入 RAG,在收到问题后找到产品手册里相关的内容再把他们一起发送给大模型。
RAG 会把产品手册分为若干个片段,收到问题后,RAG 模型再去将问题和片段进行对比,相似度高的几个片段就和问题一起发送给大模型。
通常来说,RAG 的基本流程分为两个部分,一个是数据准备部分,另一个部分是回答用户问题。数据准备部分发生在用户提问前,我们需要将用户需要的数据准备好并完成好预处理,这个部分主要有 分片 和 索引 两个环节。另一个部分发生在用户提问后,主要有 召回 、 重排 和 生成 三个环节。
逐项拆解各个环节
1、分片
这一步把文档切分成多个片段,分片的方式有很多种,比如按字数、段落、章节、页码等等。使用工具切好文档后,这个过程就结束了。
2、索引
索引主要分为两步,先通过 Embedding 将片段文本转换为向量,再将片段文本和片段向量存入向量数据库中。Embedding 后的文本向量如下:
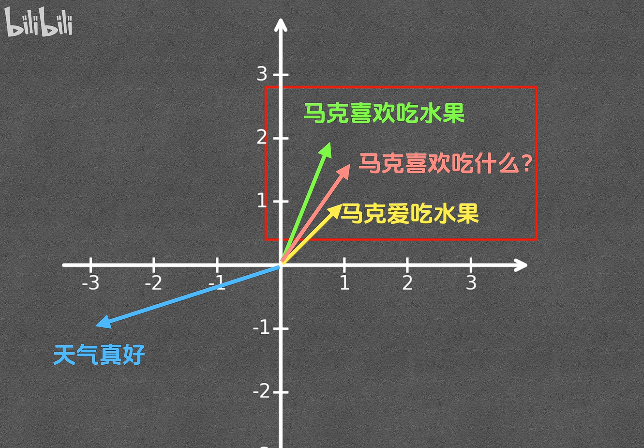
3、召回
召回就是搜索与用户问题相关内容的过程。首先,用户的问题会被发送给 Embedding 模型,Embedding 模型会将它转换为向量,然后再把它发送给向量数据库,然后向量数据库会返回若干个最相似的结果。
向量数据库使用余弦相似度、欧氏距离、点积等方法来判断向量的相似度。
4、重排
重排就是重新排序,召回返回了若干个片段,而重排就是在这里面选更少的几个片段来发送给大模型。
**重排和召回使用的文本向量相似度计算逻辑不同。**召回阶段使用的向量相似度的几种方法成本低、耗时短,但是准确率低,所以适合在大量的向量中筛选。而重排阶段一般是使用一种叫 cross-encoder 的模型来筛选,这种方法成本高、耗时长,但是准确率更高,适合精挑细选。
5、生成
最终,我们将用户问题和重排输出的参考资料发送给大模型,让大模型生成回答并发送给用户。