分类
我们之前已经学习了回归的算法,其用于预测输入一个或多个特征而输出某一个值(范围无穷大)。但是当我们想输出有限个定义的输出时(如是否电信诈骗),线性回归会导致决策边界出现偏移,降低准确率,因此我们引入逻辑回归算法用于分类。
逻辑回归
逻辑回归(Logistic Regression)是一种用于分类问题的机器学习算法,虽然名字叫“回归”,但实际主要用于二分类任务,例如:
- 垃圾邮件 / 非垃圾邮件
- 是否患病
- 用户是否会点击广告
逻辑回归的目标是根据输入特征,预测样本属于某个类别的概率,模型首先像线性回归一样计算一个线性结果
$$
z = w_1x_1 + w_2x_2 + \dots + w_nx_n + b
$$
接下来,逻辑回归使用 Sigmoid 函数 将结果转换为概率:
$$
\sigma(z) = \frac{1}{1 + e^{-z}}
$$
这个函数的输入范围从负无穷到正无穷,输出范围为(0,1),典型输入输出如下
| z | sigmoid(z) |
|---|---|
| -3 | 0.047 |
| 0 | 0.5 |
| 3 | 0.953 |
因此模型输出的是类别为 1 的概率:
$$
P(y=1|x) = \sigma(w^T x + b)
$$
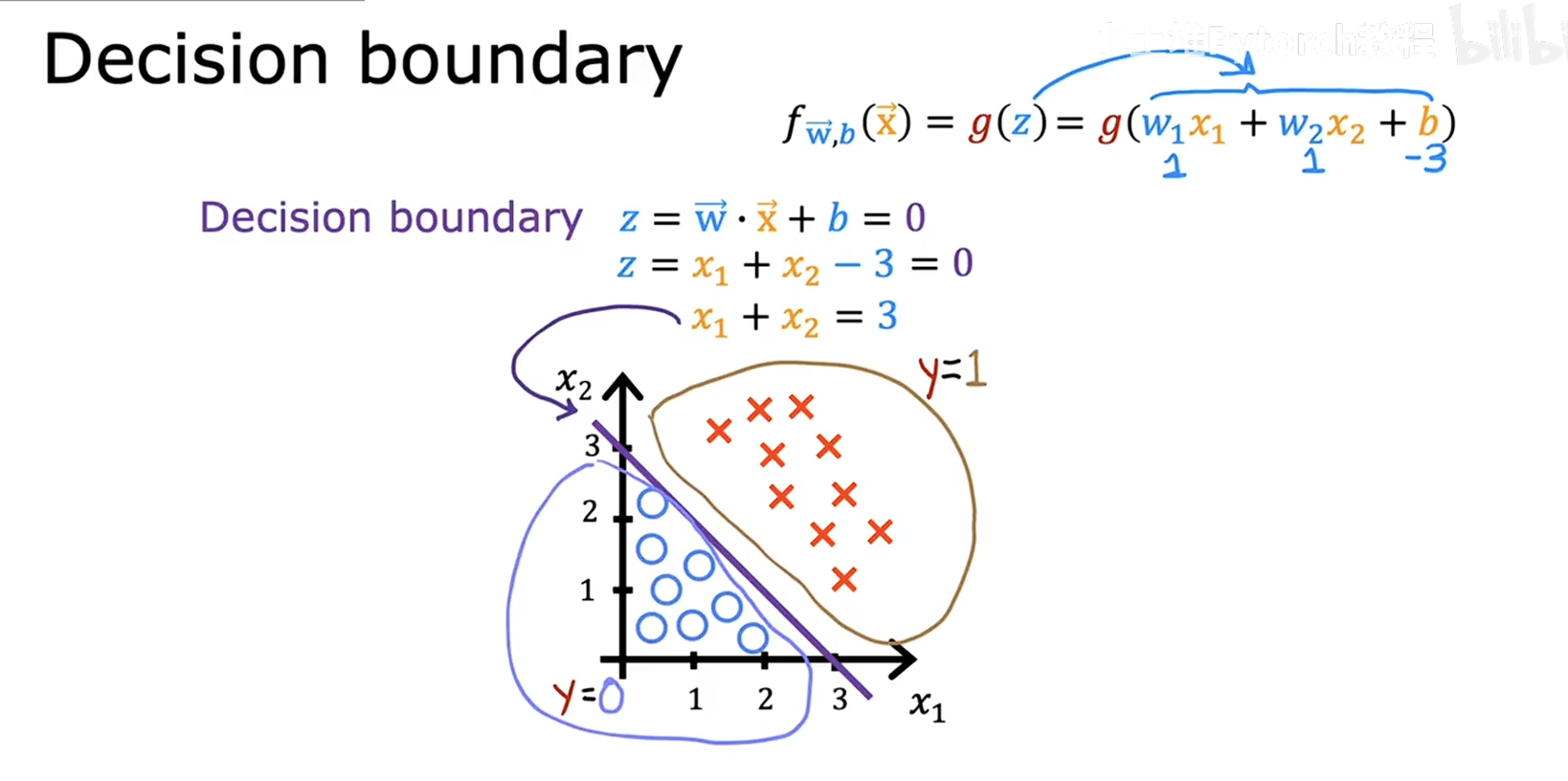
决策边界
我们已经学习了逻辑回归模型,接下来我们来认识一下决策边界(Decision Boundary),其指的是把不同样本分开的那条边界线。
我们从数学角度认识一下这个边界。已知逻辑回归模型输出的值为$P(y=1|x) = \sigma(w^T x + b)$,当阈值设置为 0.5 时,逻辑回归函数函数在 z 大于 0 时输出正分类。因此,$w^T x + b = 0$ 为决策边界公式。下面是一个简单的推导例子:
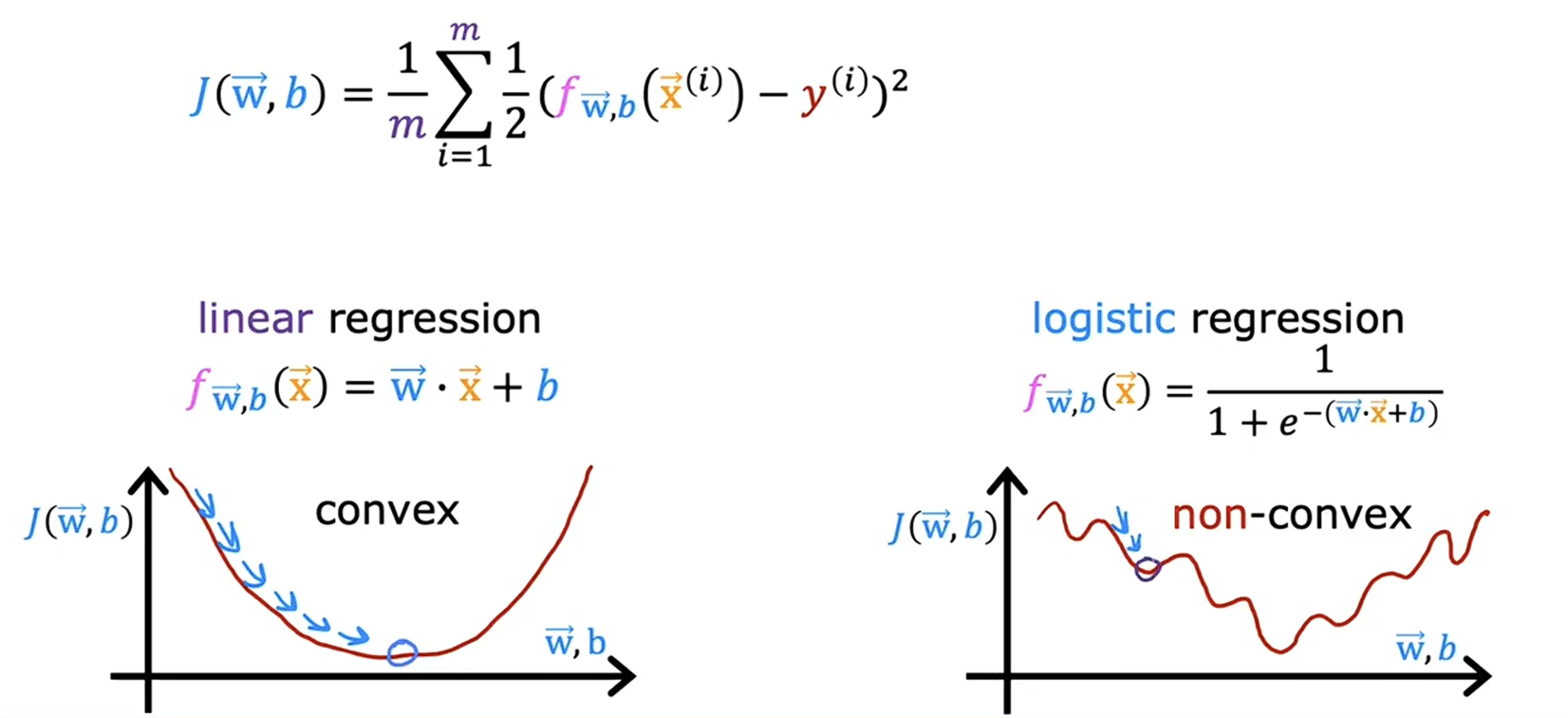
逻辑回归的代价函数
当我们在使用线性回归的代价函数代入到逻辑回归中时,会发现此代价函数会成为一个非凸函数,有多个极小值,这样会导致在梯度下降时很难找到真正的最小代价函数的值。
为了找到更好的代价函数,我们引入损失函数 (Loss) 的定义。在机器学习中,Loss 函数时用来衡量模型预测结果和真实标签之间差异的函数。对单个样本来说,损失函数就定义为模型预测值和真实值之间的差异。它与代价函数的区别是损失函数只关心单个样本,而代价函数关心整个数据集。
逻辑回归的损失函数是交叉熵损失,形式如下:
$$
L(y, \hat{y}) = - y \log(\hat{y}) - (1-y) \log(1-\hat{y})
$$
所以,逻辑回归的 cost 函数的定义如下:
$$
J(w,b)=\frac{1}{m}\sum_{i=1}^{m}L\left(\hat{y}^{(i)}, y^{(i)}\right)
$$
代入 Loss 函数后可以得到如下公式
$$
J(w,b)=-\frac{1}{m}\sum_{i=1}^{m}\left[y^{(i)} \log(\hat{y}^{(i)})+(1-y^{(i)}) \log(1-\hat{y}^{(i)})\right]
$$
逻辑回归的梯度下降实现
已知代价函数为$J(w,b)=-\frac{1}{m}\sum_{i=1}^{m}\left[y^{(i)}\log(\hat{y}^{(i)})+(1-y^{(i)})\log(1-\hat{y}^{(i)})\right]$,因此可以通过对其求关于 w 和 b 的偏导数来获得梯度下降计算量,如下
$$
\frac{\partial J(w,b)}{\partial w}=\frac{1}{m}\sum_{i=1}^{m}(\hat{y}^{(i)}-y^{(i)})x^{(i)}
$$
$$
\frac{\partial J(w,b)}{\partial b}=\frac{1}{m}\sum_{i=1}^{m}(\hat{y}^{(i)}-y^{(i)})
$$
因此我们在每一个 epoch 中更新 w 和 b 的值,直到 cost 函数降到最小值。
简单二分类代码实现
在每一个 epoch 中使用所有的数据计算梯度下降的值,训练多轮后 cost 函数收敛。
1 | import pandas as pd |
训练可视化效果如下
