多特征输入
在之前的学习中,我们学习了单特征输入(如只有房子的面积输出价格)的线性回归模型,在现实生活中,输入往往是多个的,比如有房子的面积、房龄、卧室个数等等。因此,更常见的线性回归公式如下所示
$$
f_{w,b}(X) = w_1 X_1 + w_2 X_2 + w_3 X_3 + w_4 X_4 + b
$$
为了简化这个写法,我们将其写为向量点乘形式:
$$
f_{\vec{w},b}(\vec{x}) = \vec{w} \cdot \vec{x} + b
$$
向量化
在 python 中,我们可以使用 NumPy 工具来把输入数据和参数向量化,这样可以极大的方便我们的操作和优化处理速度。具体实现如下图所示:

接下来我们深究一下为什么向量化可以使得运行速度如此之快。在平时的计算中,我们需要在多个 for 循环获取 w[i] 和 x[i] 并将它们相乘,而在 NumPy 工具中,计算机可以同时获取到 w 和 x 的所有数据并在同一时间将他们依次相乘。具体情况如下图所示。
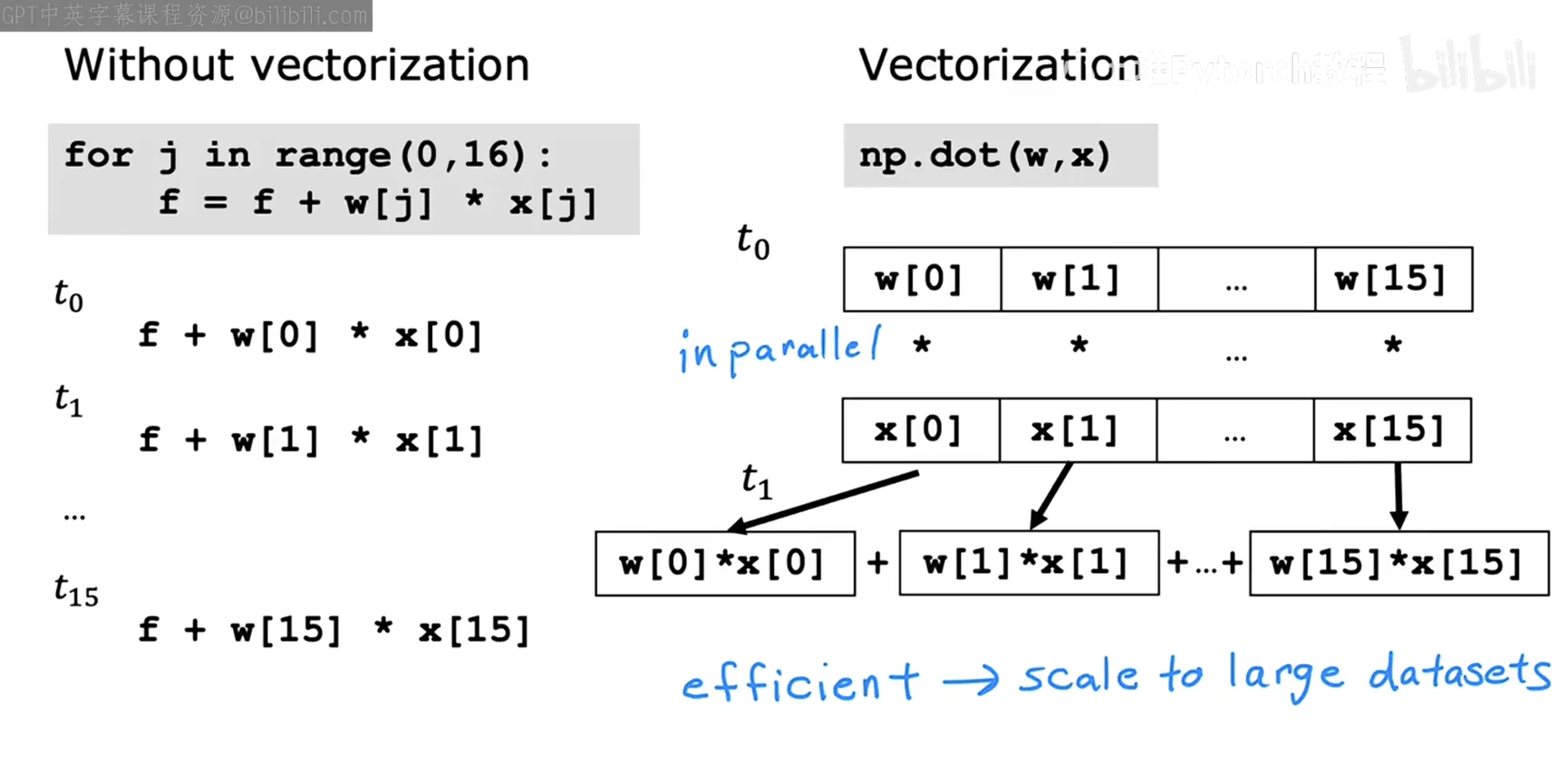
而在梯度下降的过程中,为什么使用 NumPy 比 for 循环更快呢。因为计算机可以对向量进行并行处理。

我们可以使用如下代码清晰的观察到向量化和未向量化耗时不同
1 | import numpy as np |
1 | (F:\conda_envs\machine_learning)python.exe .\train.py |
多元线性回归的数学原理
上面我们已经学习了多元特征的向量化,接下来我们来看看如何实现多元线性回归的梯度下降。
已知多元线性回归的基本函数形式如下:
$$
f_{\vec{w},b}(\vec{X}) = w_1 x_1 + \cdots + w_n x_n + b
$$
接下来我们将 w 和 b 向量化,简化这个函数形式:
$$
f_{\vec{w},b}(\vec{X}) = \vec{w} \cdot \vec{X} + b
$$
其代价函数形式为:
$$
J(w_1, \dots, w_n, b)
$$
为实现梯度下降,我们需要对代价函数求偏导,具体操作和线性回归时类似,其数学公式如下:
$$
w_j := w_j - \alpha \frac{\partial}{\partial w_j} J(w_1, \dots, w_n, b)
\quad\quad
b := b - \alpha \frac{\partial}{\partial b} J(w_1, \dots, w_n, b)
$$
因此在实际学习过程中,做的具体学习如下所示:
$$
w_1 := w_1 - \alpha \frac{1}{m} \sum_{i=1}^{m} (f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)}) x_1^{(i)}
$$
$$
w_2 := w_2 - \alpha \frac{1}{m} \sum_{i=1}^{m} (f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)}) x_2^{(i)}
$$
$$
b := b - \alpha \frac{1}{m} \sum_{i=1}^{m} (f_{\vec{w},b}(\vec{x}^{(i)}) - y^{(i)})
$$
特征缩放
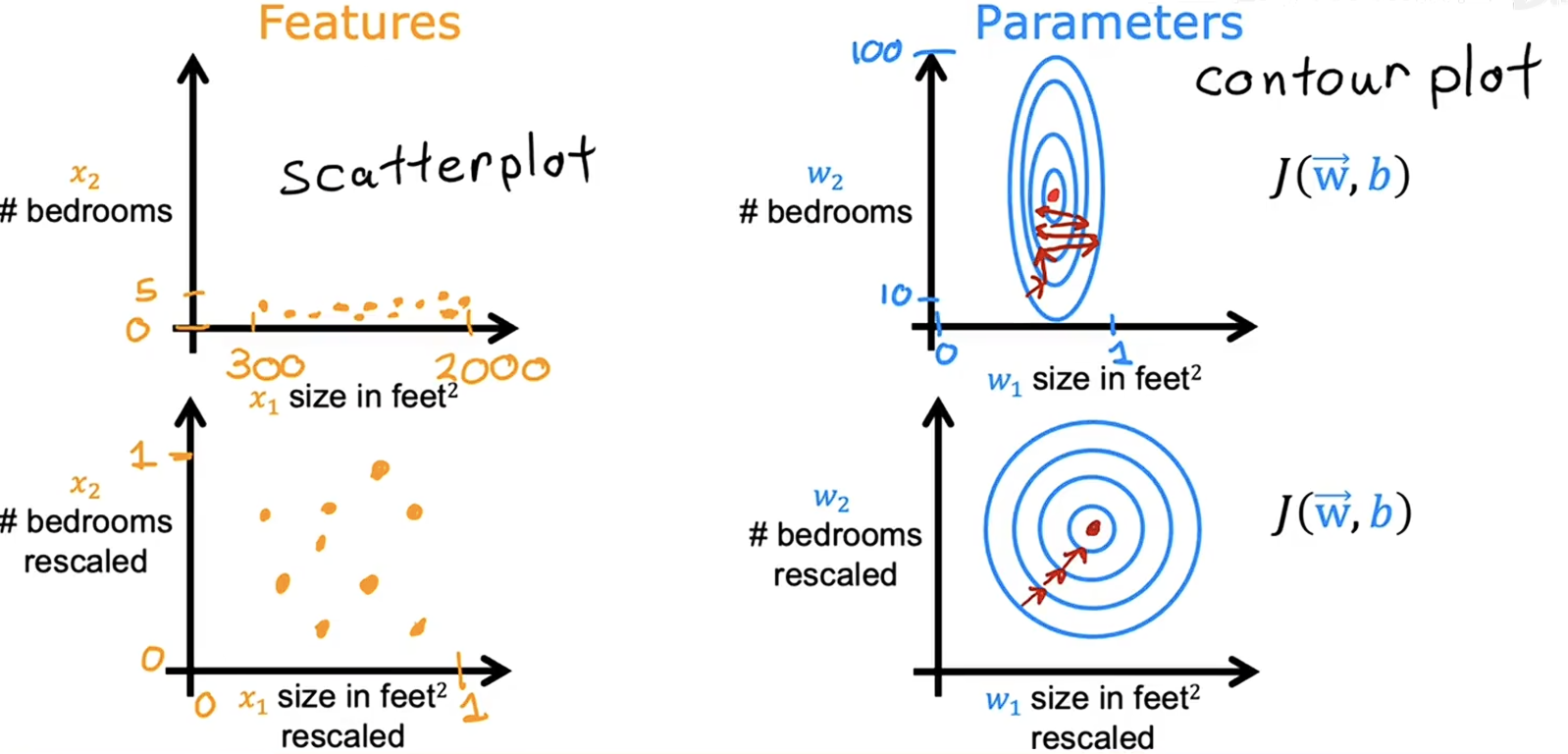
举个例子,现在有两个特征输入值,X1是房子面积,其范围在 300 - 2000 之间,而 X2 是卧室个数,其范围在 0 - 5 之间。如此大的差距会导致其代价函数的 “等高线图” 非常不标准,在梯度下降的过程中会造成效率低、来回横跳的问题。因此,我们将两个特征都缩放到 0 - 1 范围内,代价函数的 “等高线图” 更加规范,梯度下降的效率也会更高。
特征工程
特征工程(Feature Engineering)是机器学习中非常关键的一步,它指的是从原始数据中提取、选择、转换出更适合模型使用的特征的过程。它的核心目的是让模型更容易学习到数据中的规律,从而提高预测精度和泛化能力。
在机器学习中,模型的输入是特征,输出是预测结果。特征质量直接影响模型表现:好特征 → 模型更容易学到模式 → 预测准确,坏特征 → 噪声大、信息少 → 模型表现差。例如:对房价预测任务,原始数据可能有 “房屋面积” “建造年份” “街区” 等。经过特征工程可以提取 “房屋年龄” “每平方英尺价格” “是否靠近学校” 等更有意义的特征。
特征工程有以下几种常用方法:
(1) 特征选择:从已有特征中挑选对模型有用的。
- 过滤法:基于统计指标(相关系数、方差等)筛选。
- 包裹法:用模型性能评估特征组合,如递归特征消除(RFE)。
- 嵌入法:在模型训练中自动选择特征,如决策树或 Lasso 回归。
(2) 特征提取:从原始数据生成新的特征。
- 数值特征:归一化、标准化、对数变换。
- 类别特征:独热编码(One-Hot)、标签编码(Label Encoding)。
- 文本特征:TF-IDF、词向量。
- 时间序列特征:提取年、月、日、周、小时等周期性特征。
(3) 特征构造:通过已有特征组合或衍生新的特征。
- 简单数学运算:相加、相减、相乘、相除。
- 高级组合:交叉特征、分组统计(平均值、最大值等)。
- Domain knowledge:结合业务理解构造特征,如“客户活跃度 = 登录次数 × 平均在线时长”。
特征工程的目标:提高模型的预测能力、减少噪声和冗余信息、让模型更快收敛,降低计算复杂度、提供可解释性,帮助理解模型决策。