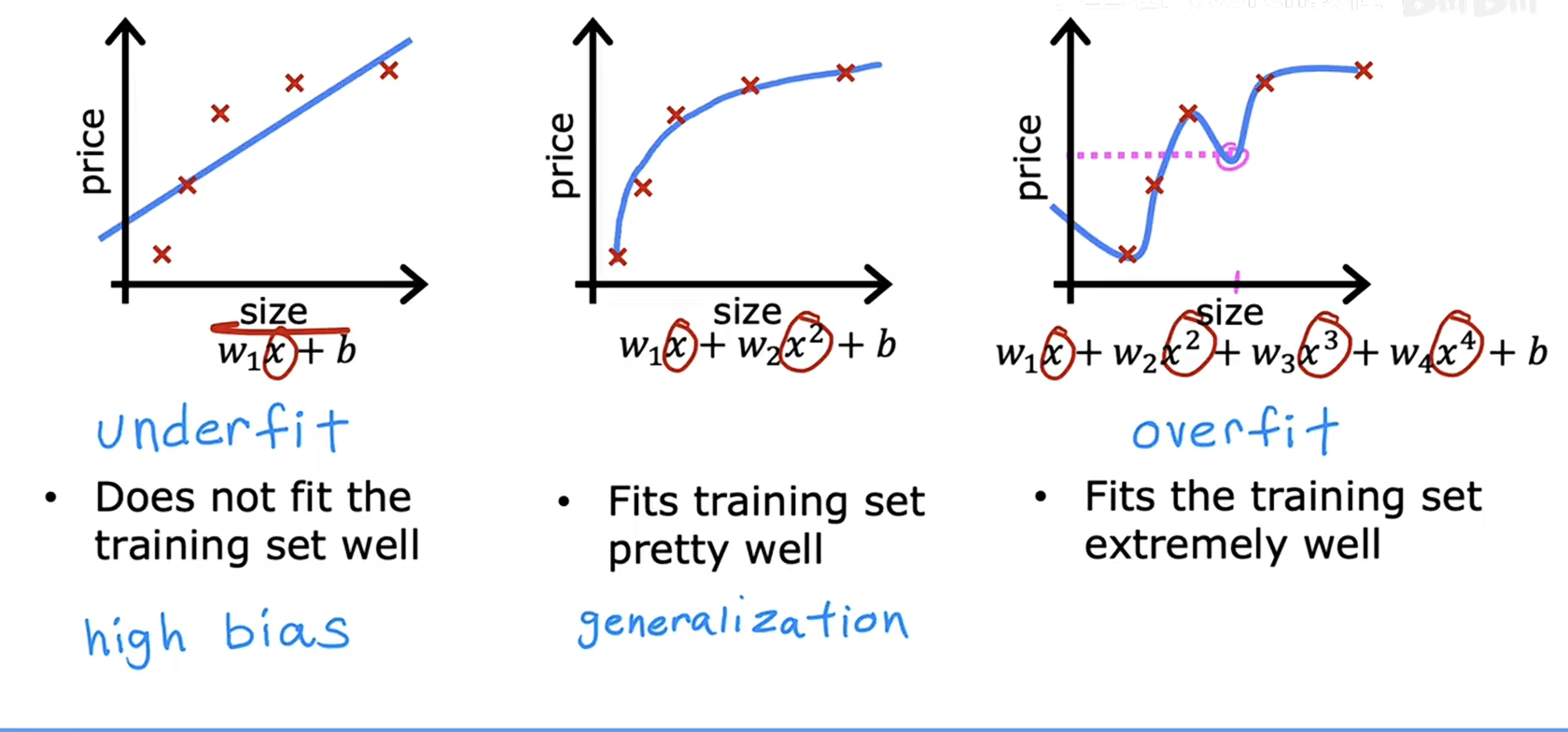
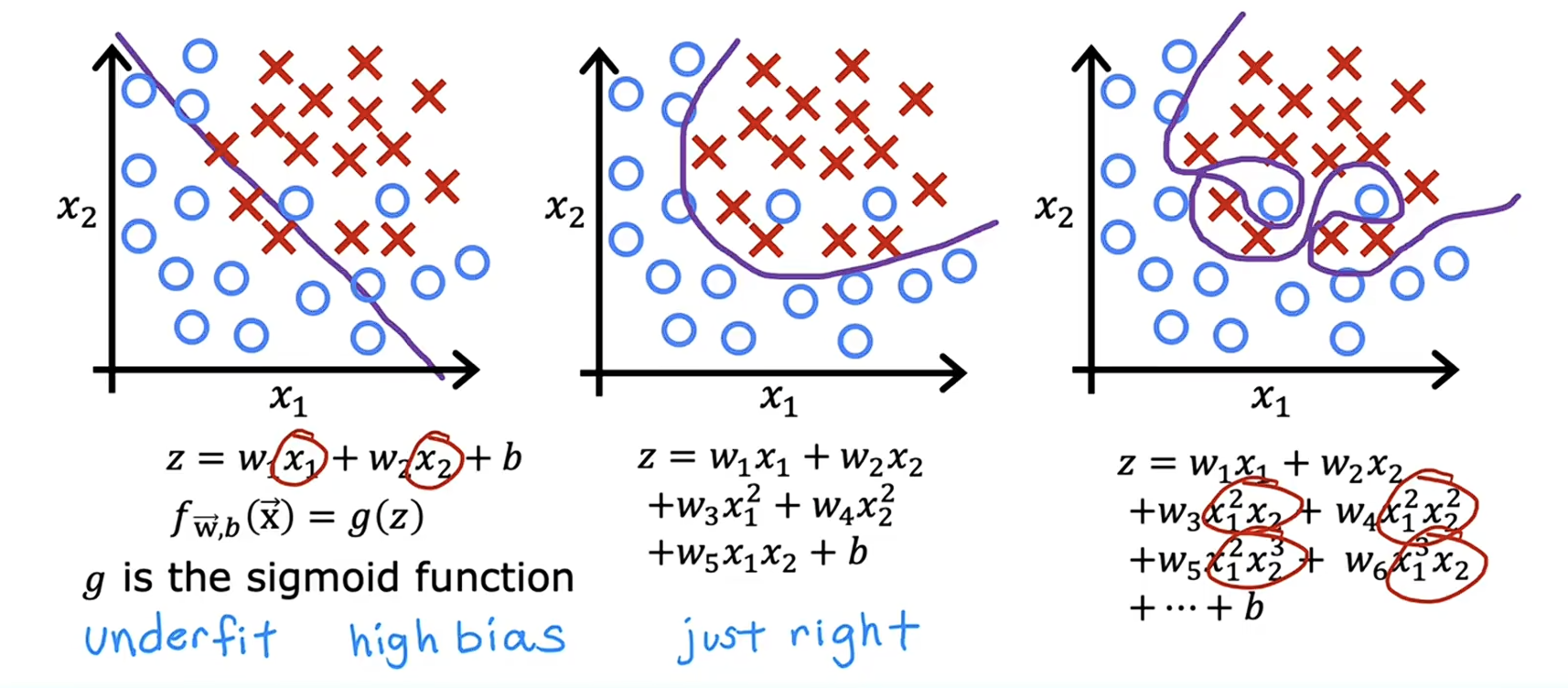
什么是过拟合 如果一个模型在训练数据上表现很好,但在未见过的新数据(测试数据)上表现很差,这就是过拟合,如下图所示,右边的模型可能在训练数据上表现得很好,但是输入测试数据会发现输出偏差很大,此时就可以认为模型发生了过拟合。
一般情况下,欠拟合会导致高偏差,过拟合会导致高方差。
图 1 线性回归过拟合
图 2 逻辑回归过拟合
如何发现并解决过拟合 一般情况下,我们可以通过划分 训练集/测试集 来判断一个模型是否过拟合。如果一个模型训练集和测试集误差都高,那么是欠拟合;如果一个模型测试集误差低,训练集误差高,说明其过拟合了。
一般情况下我们可以通过以下几个方法来解决过拟合:
增加训练数据
降低模型复杂度
正则化
减少无关特征
正则化 正则化(Regularization) 是一种在模型训练时 限制模型复杂度 的方法,目的是 防止过拟合,提高模型的泛化能力。简单来说,正则化就是在损失函数中加入一个惩罚项,让模型参数不要变的过大。
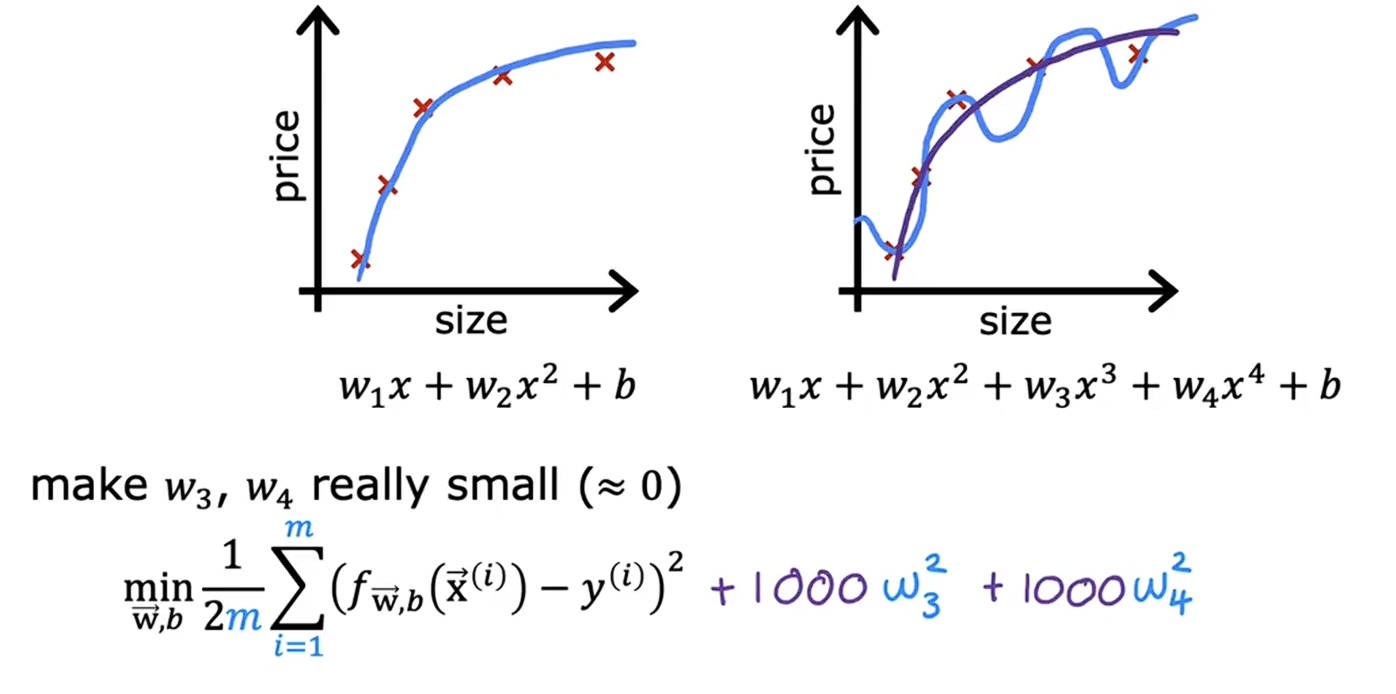
正则化基本原理如下图所示,当 w3 和 w4 对模型影响较大时,我们可以在后面加上一个 1000w3^2 和 1000w4^2,这样在梯度下降的过程中模型就会将 w3 和 w4 的影响不断降低。
图 3 正则化基本原理
正则化的基本形式可以如此推导,原来的损失函数如下:
$$
加入正则项后如下:
$$
我们最常使用的正则化有以下两种
L2 正则化(Ridge) $$
新的损失函数如下所示
$$
因此,对应的代价函数如下所示
$$
这种正则化方法是会让参数变小,但不至于变为 0,是最常用的一种正则化方式。
L1 正则化(Lasso) $$
新的损失函数如下所示
$$
因此,对应的代价函数如下所示
$$
其特点为会让部分参数变成 0,可以做特征选择。
λ 的作用如下
λ
效果
λ = 0
没有正则化
λ 小
轻微限制
λ 大
强烈限制
带正则化的线性回归梯度下降 当我们使用 L2 正则化时,只对 w 进行正则化,不对 b 进行正则化。正则化后的代价函数如下:
$$
因此,其对应线性回归梯度下降的计算如下:
$$
$$
带正则化的逻辑回归梯度下降 正则化逻辑回归和正则化线性回归梯度下降的计算公式非常相似。已知经过 L2 正则化后的逻辑回归代价函数如下
$$
因此,我们对 wj 求偏导,可以得到梯度下降更新如下
$$
$$
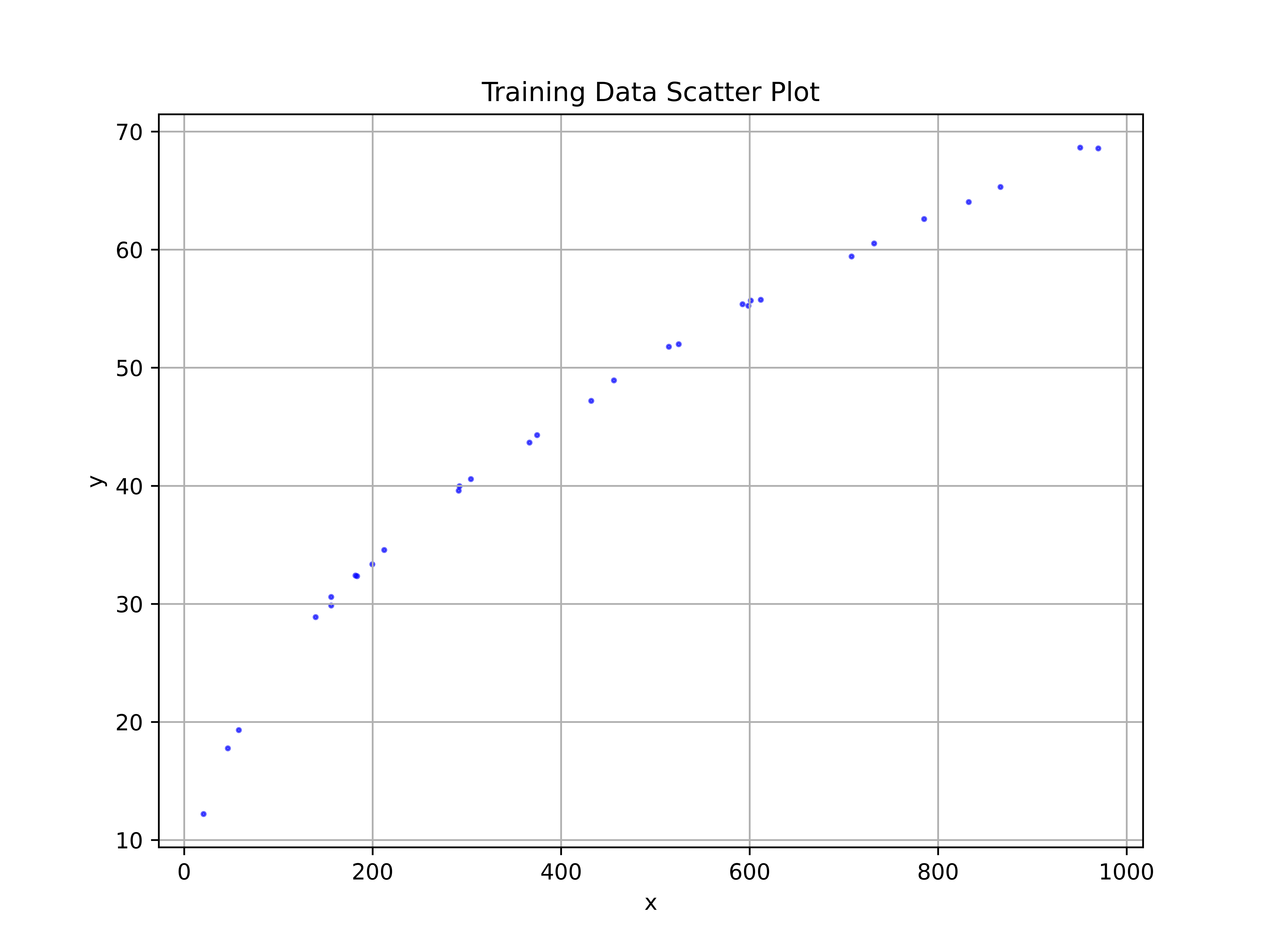
正则化对比实验 使用 ChatGpt 生成一组随机的单输入单输出数据作为训练样本,其散点图如下:
图 4 原始数据散点图
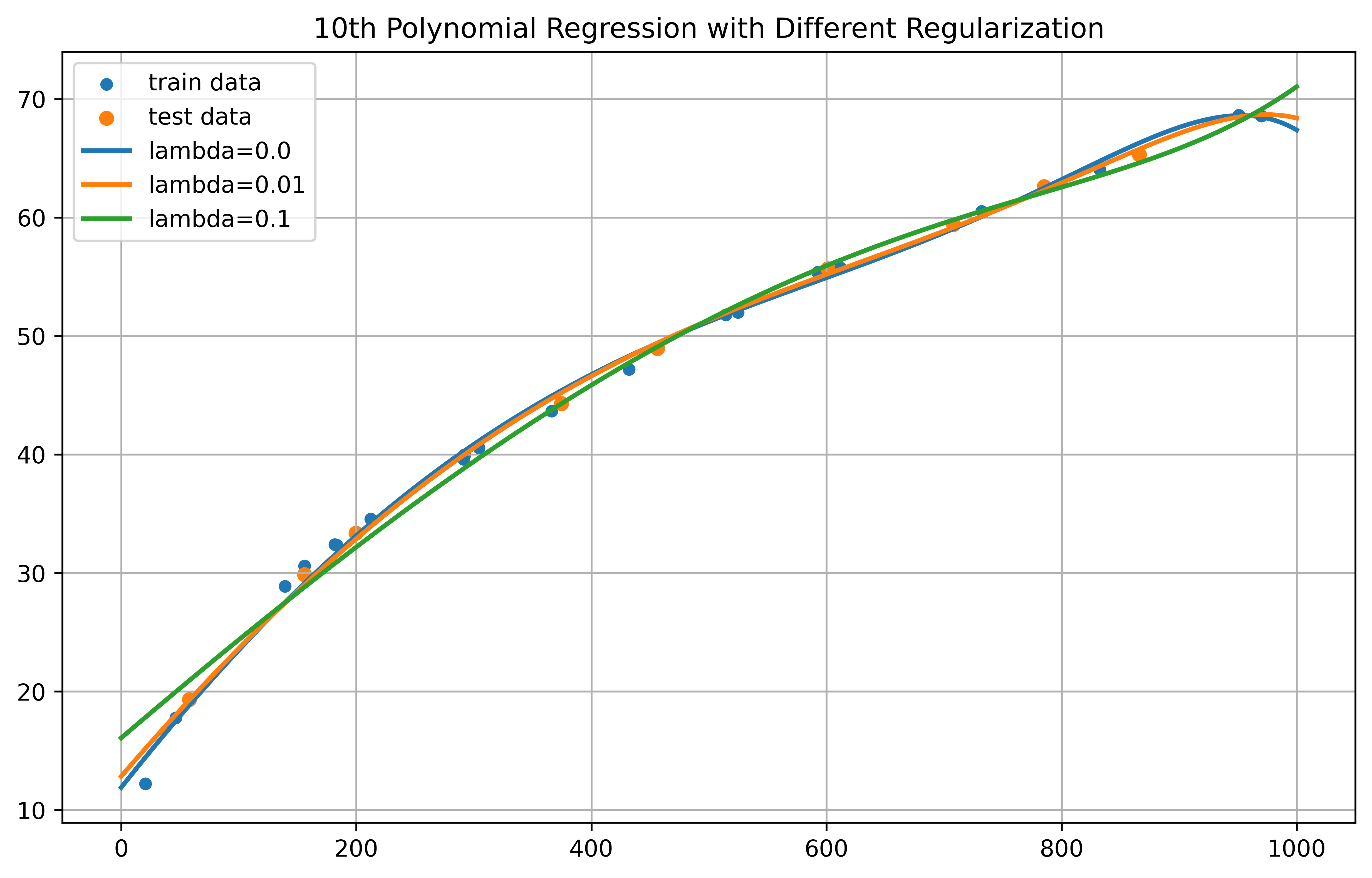
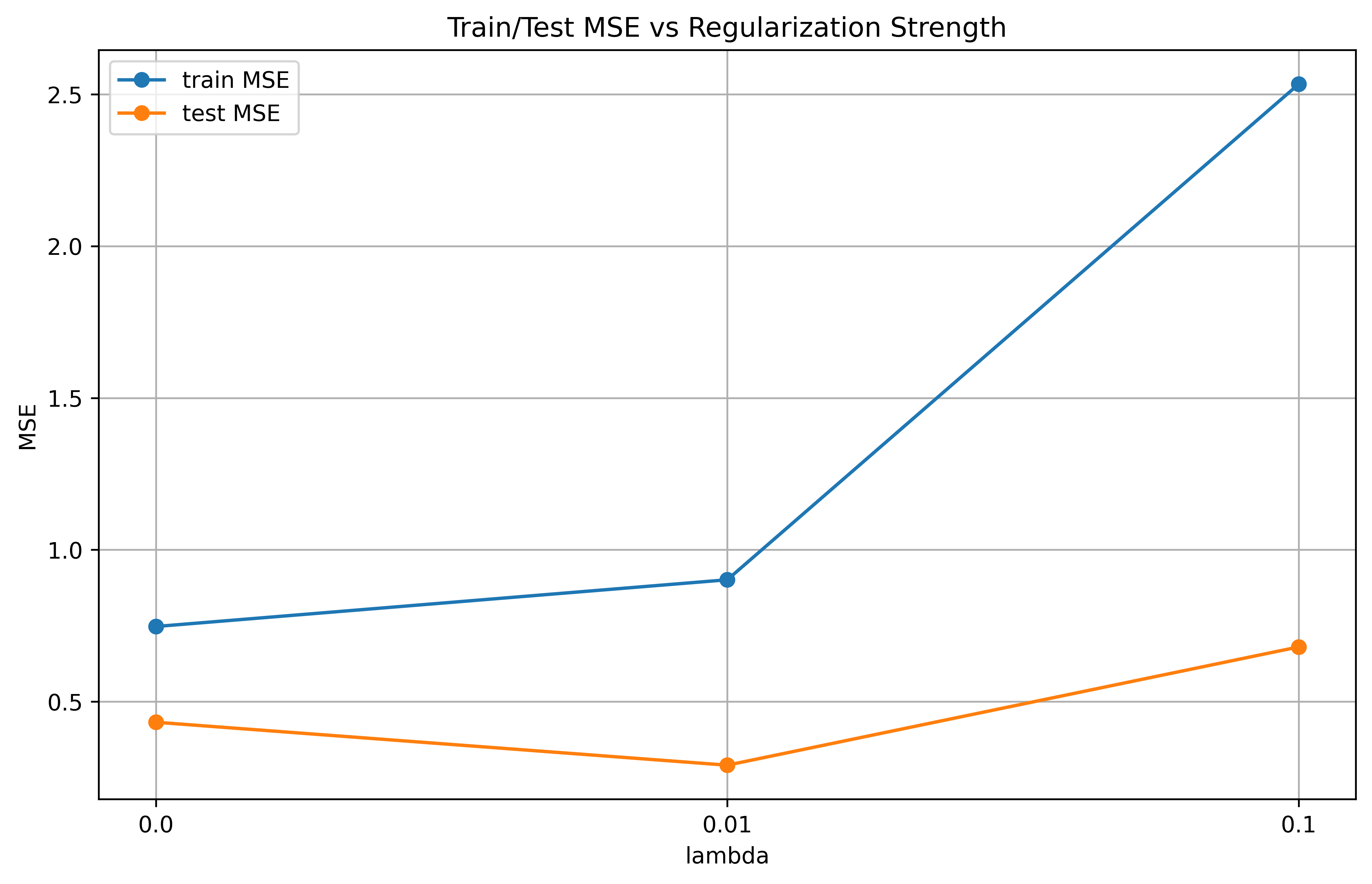
接下来我们分别将 λ 设置为 0、0.01、0.1 进行训练,通过数据可视化得到以下结果
图 5 拟合曲线对比
图 6 测试集训练集误差对比
可以看出,当 λ 取值为 0.1 的时候测试集误差最小、效果最好。
完整训练代码由ChatGPT生成,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 import numpy as npimport pandas as pdimport matplotlibmatplotlib.use("Agg" ) import matplotlib.pyplot as pltnp.random.seed(42 ) m = 30 x = np.random.uniform(0 , 1000 , m) noise = np.random.normal(0 , 0.3 , m) y = np.log(x + 1 ) + 2 * np.sqrt(x) + noise data = pd.DataFrame({"x" : x, "y" : y}) data.to_csv("data.csv" , index=False ) idx = np.random.permutation(m) train_size = int (0.7 * m) train_idx = idx[:train_size] test_idx = idx[train_size:] x_train = x[train_idx] y_train = y[train_idx] x_test = x[test_idx] y_test = y[test_idx] degree = 10 def poly_features (x, degree ): X = np.zeros((len (x), degree)) for i in range (degree): X[:, i] = x ** (i + 1 ) return X X_train_raw = poly_features(x_train, degree) X_test_raw = poly_features(x_test, degree) mean = X_train_raw.mean(axis=0 ) std = X_train_raw.std(axis=0 ) std[std == 0 ] = 1.0 X_train = (X_train_raw - mean) / std X_test = (X_test_raw - mean) / std def train (X, y, alpha=0.01 , epochs=200000 , lam=0.0 ): m, n = X.shape w = np.zeros(n) b = 0.0 cost_history = [] for epoch in range (epochs): y_pred = X @ w + b error = y_pred - y dw = (1 / m) * (X.T @ error) + (lam / m) * w db = (1 / m) * np.sum (error) w -= alpha * dw b -= alpha * db y_pred_new = X @ w + b cost = (1 / (2 * m)) * np.sum ((y_pred_new - y) ** 2 ) + (lam / (2 * m)) * np.sum (w ** 2 ) cost_history.append(cost) return w, b, cost_history def mse (X, y, w, b ): y_pred = X @ w + b return np.mean((y_pred - y) ** 2 ) lams = [0.0 , 0.01 , 0.1 ] results = [] for lam in lams: w, b, cost_history = train(X_train, y_train, alpha=0.01 , epochs=200000 , lam=lam) train_mse = mse(X_train, y_train, w, b) test_mse = mse(X_test, y_test, w, b) results.append({ "lam" : lam, "w" : w, "b" : b, "cost_history" : cost_history, "train_mse" : train_mse, "test_mse" : test_mse }) print (f"lambda={lam:.2 f} , train_mse={train_mse:.6 f} , test_mse={test_mse:.6 f} " ) best_result = min (results, key=lambda r: r["test_mse" ]) print ("\nBest lambda based on test MSE:" )print (f"lambda={best_result['lam' ]} , train_mse={best_result['train_mse' ]:.6 f} , test_mse={best_result['test_mse' ]:.6 f} " )x_plot = np.linspace(0 , 1000 , 500 ) X_plot_raw = poly_features(x_plot, degree) X_plot = (X_plot_raw - mean) / std plt.figure(figsize=(10 , 6 )) plt.scatter(x_train, y_train, s=20 , label="train data" ) plt.scatter(x_test, y_test, s=30 , label="test data" ) for r in results: y_plot = X_plot @ r["w" ] + r["b" ] plt.plot(x_plot, y_plot, linewidth=2 , label=f"lambda={r['lam' ]} " ) plt.legend() plt.title("10th Polynomial Regression with Different Regularization" ) plt.grid(True ) plt.savefig("regularization_compare.png" , dpi=600 , bbox_inches="tight" ) plt.close() lam_labels = [str (r["lam" ]) for r in results] train_mses = [r["train_mse" ] for r in results] test_mses = [r["test_mse" ] for r in results] plt.figure(figsize=(10 , 6 )) plt.plot(lam_labels, train_mses, marker="o" , label="train MSE" ) plt.plot(lam_labels, test_mses, marker="o" , label="test MSE" ) plt.xlabel("lambda" ) plt.ylabel("MSE" ) plt.title("Train/Test MSE vs Regularization Strength" ) plt.legend() plt.grid(True ) plt.savefig("mse_compare.png" , dpi=600 , bbox_inches="tight" ) plt.close() print ("\n已保存:regularization_compare.png" )print ("已保存:mse_compare.png" )