项目目标
导入一份消费流水数据,自动分析:
- 每月总支出
- 每类消费占比
- 哪些月份花钱异常
- 哪些类别支出增长明显
- 自动生成消费分析报告
开始做
excel 转换为 CSV
首先我们获取数据,在微信中导出近一个月的账单,发现有许多数据,如交易时间、交易类型、交易对方、商品收/支 等等。但并不是所有的信息我们都需要使用,例如交易订单号我们就不需要。因此我们先读取 excel 表格提取出有用的信息再转换成 csv。
创建 src/data_loader.py 文件,写入三个工具,分别问读取、清洗、转化。读取函数读入 excel 表格并将其转化为 dataframe 格式,然后清洗步骤筛选出支付成功的信息并将表头重命名为英文,最后转化成 csv 并导出,方便后续处理。
数据分类
接下来,我们应该将这些数据分类为具体的几种类别。我的想法是我们先根据关键字分类,不能分类的再交给 LLM 具体分类。我们创建固定类别如下:
1 | CATEGORIES = [ |
接下来我们使用简单的关键字匹配函数分类数据。匹配完成后可以看出匹配率还是很高的。接下来我们可以使用 LLM 模型再去给待分类的匹配。

但是这样也存在问题啊,LLM 分类太慢了,如果有很多记录,还得一个个等!我们需要优化他的分类速度。
我们是否可以通过聚类的机器学习算法来将这些待分类的分到一起,然后再喂给 LLM 分类呢?结合之前做过的 RAG,我想到可以使用 embadding 模型将这些语句向量化,然后再将其进行 K-Means 聚类算法,最后将整个聚类喂给 LLM 不就可以了吗?
经过代码验证,这样的速度确实快了许多,接下来让我们看看更多的技术细节。
在 K-Means 的过程中,聚类数量我们使用了自适应的算法,具体代码如下:
1 | target_cluster_size = 8 |
这样我们就可以根据待分类数量自动估算簇的数量,保证其每个簇中大约有 8 条信息。
接下来,为了减少 LLM 对每个簇的推理量,我们在每个簇中抽样发送给 LLM,这样比每一条都发给 LLM 进行推理分析快了不少。
数据分析
接下来我们实现月度支出分析、消费类别占比分析、每月各类别支出分析、Top 商家分析等等。接下来我们看看每一个如何具体实现。
0、转换格式
将日期转换为可以识别的年月日、再将 amount 转换为数字,并删除 date 和 amount 为空的行。
1 | def load_transactions(csv_path: str) -> pd.DataFrame: |
1、月度总支出分析
将消费数据按月份排序、求和并返回。
1 | def analyze_monthly_expense(df: pd.DataFrame) -> pd.DataFrame: |
2、消费类别占比分析
按照 category 分类并留下 amount 数据,再对每一组的 amount 进行求和,然后从大到小排列,最后整理成普通表格。最后添加新的一列 ratio 表示每一项的占比。
1 | def analyze_category_expense(df: pd.DataFrame) -> pd.DataFrame: |
3、消费商家排行
按照商家分组后,对其金额求和,再将其排序后保留顶部 top_n 个,最后重新整理成表格并返回。
1 | def analyze_top_merchants(df: pd.DataFrame, top_n: int = 15) -> pd.DataFrame: |
4、单笔异常消费检测
这里使用了 IQR 检测方法,会去数据的下四分位数 Q1 和上四分位数 Q3,IQR = Q3 - Q1,于是异常消费的上边界就在 Q3 + 1.5 * IQR。超过这个边界的消费就可以认为是异常消费。
1 | def detect_abnormal_transactions(df: pd.DataFrame) -> pd.DataFrame: |
5、异常月度检测
这里用的是 z_score 计算。首先计算这份数据的均值和标准差,接下来通过此公式计算 z_score:
z_score = (当前月份支出 - 平均月支出) / 标准差
表明了这个月的支出距离平均水平有多少个标准差,在本次分析中,我们筛选出比平均水平高出 2.5 个标准差的月份。
1 | def detect_abnormal_months(monthly_expense: pd.DataFrame) -> pd.DataFrame: |
可视化
新建 data_visiable.py 文件,并使用 matplotlib 工具将分析得到的数据进行可视化,结果如下所示:
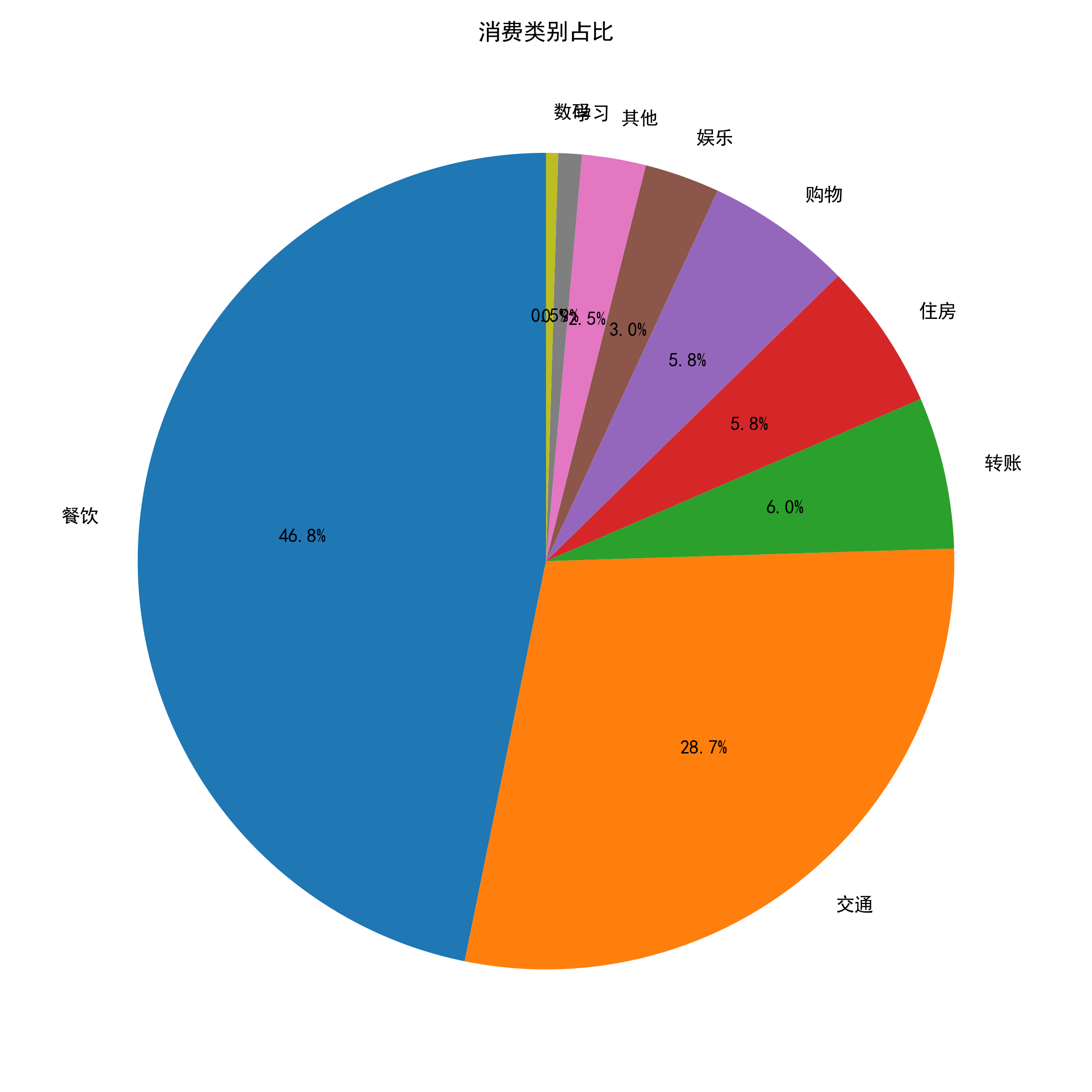
生成自然语言报告
新建 report_generator.py 工具,先使用 pandas 工具分析数据,再调用本地 LLM 模型生成语言报告。
完整代码仓库如下
1 | https://github.com/hccc1203/Personal_expense_analysis_sys |