监督学习
监督学习指的是训练从 input 到 指定 output label 的过程,在训练过程中,给予程序输入和对应的正确输出,最终使程序可以仅凭输入给出准确的预测。例如垃圾邮件过滤器、语音识别、机器翻译、自动驾驶等等。
例如我们得知了部分房子的尺寸与其对应的卖价,学习程序可以通过分析这些数据来得到其中的关系,然后我们再输入一个全新的尺寸,就可以得到其对应的大概卖价。
这种房价预测就是监督学习的回归,是指我们可以从无限多个可能的数字中预测一个数字,就如例子中的房价。
另一种监督学习的类型叫做分类,以乳腺癌检测为例,这就是一种分类模型。在训练机器学习系统时,输入患者的就诊记录(肿瘤大小等数据)和对应的结果(如恶性、良性),与回归不同的是,我们预测结果的输出只能在离散且有限的结果中。
无监督学习
在监督学习之后,最广泛使用的是无监督学习。
在无监督学习中,我们得到的数据没有任何与其对应的输出标签,在上面的例子中,假设我们已经得到了患者的肿瘤尺寸和年龄信息,但是没有对应的恶性、良性信息。
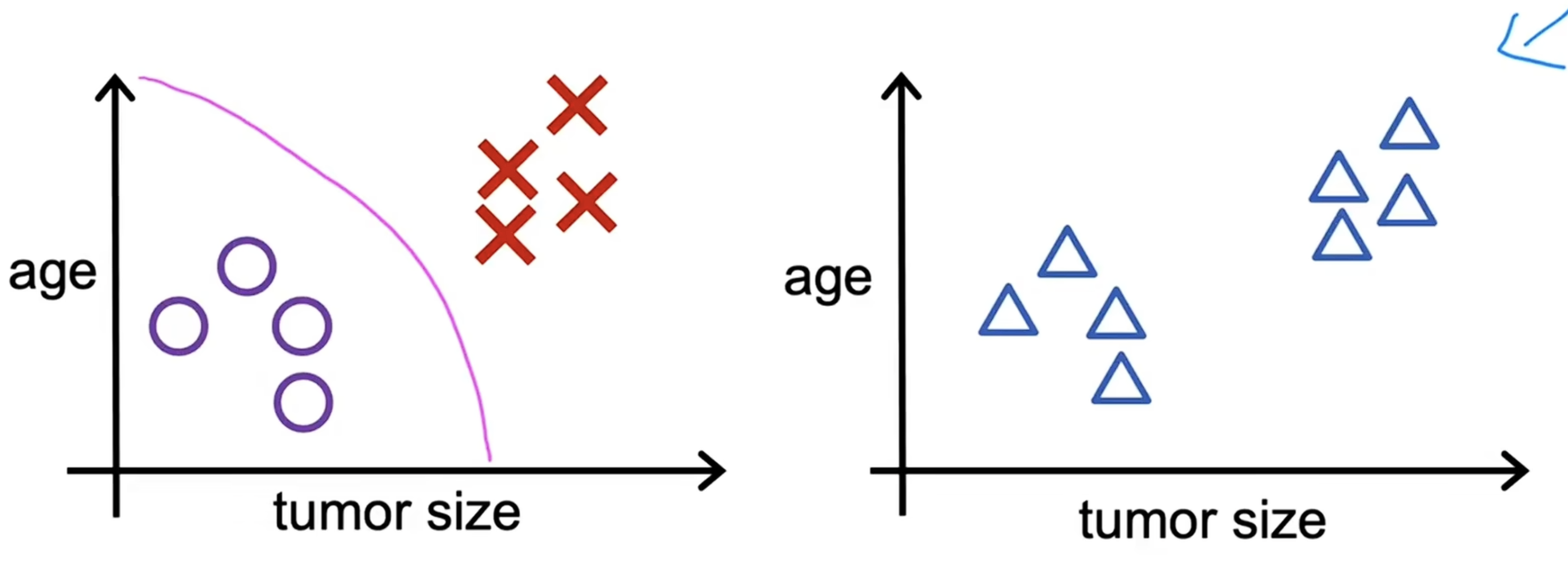
在无监督学习中,检测算法不被要求检测肿瘤是否 良性/恶性,我们需要算法自己找出数据中可能存在的模式或结构。
无监督学习又被分为 聚类、异常检测、降维 三种。
聚类算法可以决定输入的未标记数据集可以分到两个或更多的组中,举个例子,这种算法用于谷歌新闻,谷歌新闻每天阅读数十万条信息并将其分类到不同的组中。
降维的目标是把高维数据转换到低维,例如 100维特征 → 2维,其用途主要是可视化、数据压缩、去噪等等。
异常检测的目标是找到 异常样本,应用在信用卡欺诈、工业故障检测、网络攻击检测等等。
代价函数
代价函数(cost-function)是衡量模型在 整个训练数据集上的误差大小,训练的目标就是让这个值 尽可能小。
$$
J(\theta) = \frac{1}{m} \sum_{i=1}^{m} L(y_i, \hat{y}_i)
$$
在线性回归中,我们常常使用样本平均方差来表示代价函数,如下
$$
J(w,b) = \frac{1}{2m} \sum_{i=1}^{m} \left(\hat{y}^{(i)} - y^{(i)}\right)^2
$$
我们已经了解了代价函数的定义。当我们在训练一个线性回归模型时,选取不同的 w 和 b 会对代价函数产生不同的影响。当代价函数值最小时,此时的 [w,b] 就是最合适的值。
梯度下降
梯度下降算法在机器学习中广泛使用于训练模型。在线性回归模型中,我们有一个代价函数 J(w,b),并且我们想要得到这个函数的最小值和其 w,b 的取值。
以线性回归举例,使用梯度下降时,我们先把 w,b 的初始值设置为 0,并且每次都尝试减少代价函数 J 的值,知道 J 最终接近或稳定在最小值。对于一些 J ,其可能不只有一个最小值,可视化效果如下图所示
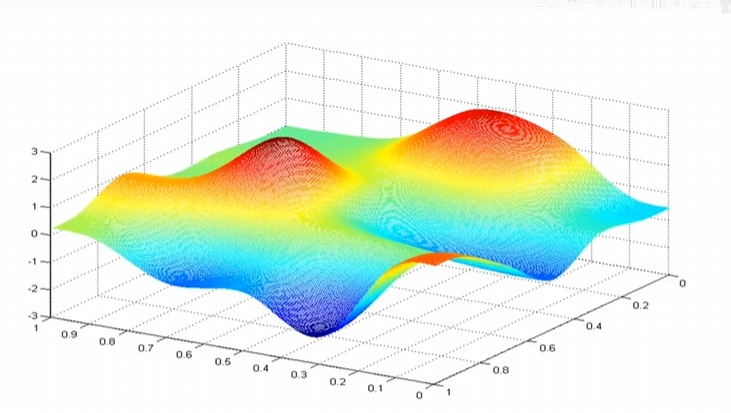
在这样的图中,如果我想尽可能快的从一个点到最小值,我们应该选择负梯度方向(下降最快的方向)。但是当你的起点不同,可能会达到不同的局部最小值。
那我们如何实际实现梯度下降算法呢?在实际计算中,我们每一步通常这样计算:$w = w - \alpha \frac{\partial}{\partial w} J(w,b)$,其中 α 就是学习率,其通常是一个介于 0 - 1 之间的小数,其作用就是控制你每次改变走的每一步。同理,对应另一个参数计算公式如下:$b = b - \alpha \frac{\partial}{\partial b} J(w,b)$。
在实际的代码书写过程中,我们应该同时更新 w 和 b 的值。如果你先更新了 w 的值,再通过上面的公式计算新的 b 就会受到 w 更新的影响。其正确逻辑如下:
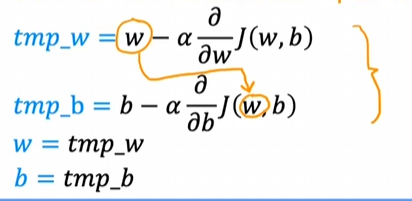
学习率
正如上文所说,学习率控制的是梯度下降每一步的大小。如果学习率过小,会导致导数项乘一个非常小的数,因此会采取一个非常小的步长,整个下降过程会非常的缓慢。如果学习率过大,当你非常接近最小值时,会导致你大步更新参数,从而超过最小值,然后一直在最小值附近震荡,无法收敛至最小值。因此,在实际训练中需要选择一个合适的学习率,使得梯度下降既能较快收敛,又不会发生震荡或发散。